As sand can fill the open space in a jar of stones, artificial intelligence (AI) makes its way into every business niche. From coding copilots and AI text generators to real-time ad bidding systems and industrial automation, we’ve seen hundreds of new AI use cases emerge in less than a decade.
Granted, you no longer need to be a well-funded Big Tech company or a major research institution to develop AI applications. Thanks to a plethora of open-source ML frameworks and low-cost AI development tools, anyone—from a new gaming startup to a legacy financial institution—can figure out how to make an AI product.
In this post, you’ll learn about:
- The most viable AI use cases across industries
- Key steps in the AI project lifecycle (with best practices)
- Top AI tools, frameworks, and platforms to streamline adoption
The best uses of AI for strategic investments
AI had a breakthrough moment in 2023 with the public launch of generative AI (artificial intelligence) tools like ChatGPT, Bard, and DALL·E, among others. However, artificial intelligence application development goes well beyond Gen AI.
Other viable use cases for AI application development include computer vision, intelligent process automation, predictive and prescriptive analytics, natural language processing, and industrial automation.

Different AI technologies can contribute over $15.7 trillion to the global economy by 2030. That’s more than the combined output of China and India.
Even today, established AI startups already boast impressive valuations. OpenAI is worth an estimated $100 billion. AI (artificial intelligence), data, cloud data company Databricks is valued at $43 billion, and autonomous driving startup Cruise was last valued at $30 billion, according to Crunchbase. Overall, 15 new AI startups became unicorns in 2023, collectively worth over $21 billion.
AI application development also ranks high among enterprises across sectors, with 42% saying they already run AI systems in production. Walmart, for example, uses conversational AI to provide customer support and help shoppers locate items in store. JP Morgan Chase, in turn, uses AI models for compliance management, fraud detection and prevention, and customer support, among other use cases.
AI has also made a transformative impact in the MarTech sector, helping companies build better multi-channel attribution models and offer dynamic creative optimization (DCO). Overall, 60% of CFOs at tech companies named AI as the #1 strategic investment priority for 2024.
Reassured by the early successful pilots, business leaders amp up their spending on AI (artificial intelligence). According to BCG, 85% plan to increase their investments in AI and Gen AI in 2024 to pursue new use cases and/or scale existing deployments. Reflecting this trend, enterprise spending on generative AI solutions worldwide is expected to see a significant surge. By 2027, it’s projected to reach $151.1 billion, growing nearly eightfold from its total in 2023, according to the International Data Corporation. This substantial growth underscores the expanding role of generative AI in various industries.

Siemens Mobility researches safe artificial intelligence for driverless trains and air-free brake systems. Credit Karma is working on a GPT-like financial assistant which will help users optimize their spending and savings. Travel companies like Expedia and Booking also released personalized AI assistants for travel planning.
2024 promises to be another groundbreaking year for AI as organizations move pilots from the labs to the production environment.
As Gen AI becomes more mature, we expect more assistants and “copilots” to emerge, covering a wider range of processes—from cybersecurity and content creation to lead scoring and sales enablement. Voice and video generation will likely be the new frontiers for gen models. For example, Runway already produces effective generative video models, while ElevenLabs works on audio synthesis. The success of new Gen AI products, however, hinges on whether these tools can be secure and reliable. AI chatbots are easy to hack, and they can often produce hallucinations.
Industrial automation and robotics will also advance, thanks to AI. Thanks to increased connectivity, abundance of data, and model sophistication, businesses can deploy AI systems to perform complex, labor-intensive tasks. Caterpillar, for example, created large-scale AI systems to track the performance of 1.4 million connected assets and provide users with real-time condition monitoring and predictive maintenance insights. Samsung, in turn, plans to use AI to optimize its chip design, manufacturing, and packaging processes to minimize waste and product defects.
New advancements are on the way, too. In June 2023, DeepMind released Robocat, a robot that learns to control many of its arms by using its data from trial and error attempts. DeepMind has also released RT-X—a model for different types of robots—and a new general-purpose training data set. Open-source models dramatically accelerate AI application development, so we’ll likely see further innovation in robotics this year.
Generally, AI will take over a wider range of tasks, augmenting the human workforce. Forrester expects that 60% of workers will rely on AI to perform their jobs, at least in some capacity. From task automation and smarter business intelligence (BI) to knowledge management, content creation, and personalized customer service, AI has a massive potential to improve staff efficiency and shave off some operating costs.
AI adoption could boost productivity growth by 1.5 percentage points per year over ten years and raise global GDP by 7% — an equivalent of $7 trillion in additional output.
From business case to successful AI implementation: How to build an AI system
Although most business leaders are bullish about building AI solutions, fewer are satisfied with their progress. According to an IBM survey, 40% of larger enterprises are only experimenting with AI, but haven’t yet deployed an AI-based project in production. Limited AI expertise (33%), high data complexity (25%), and ethical concerns (23%) are among the top-cited barriers.
[cta-with-description title=”Looking for skilled AI engineers?” description=”Partner up with Xenoss dedicated development team” url=”https://xenoss.io/#contact” buttontext=”Get in touch”]
Indeed, developing an AI requires both operational and technological readiness. It isn’t a marathon that demands research, evaluation, and experimentation to determine the role of AI in your business and ensure secure, ethical, and ROI-driven solution deployment.
To help you out, the Xenoss team created a simple framework, explaining how to build an AI system. It covers the key considerations, challenges, and aspects of the AI project cycle.
1. Formalize a business case
AI has multi-faceted capabilities. Your goal is to determine its role in your operations. The easiest way to approach this is by going backward from your objective(s): What do you want to achieve with AI implementation?
Think in terms of precise problems and measurable outcomes. Half of AI-mature organizations rely on a combination of technical and business metrics to assess the ROI of implemented AI use cases. They’re also more likely to use customer success-related business metrics to inform their AI strategy.
Seek out use cases where you’ve already seen a convincing demonstration of the technology’s potential. In the finance sector, AI has proved its merit for fraud detection. Machine learning and deep learning models outperform traditional rules-based fraud detection systems by offering a lower rate of false positives and showing better results in recognizing new types of fraud. For example, users of Stripe Radar and Stripe Payments (both powered by AI) report a below 0.2% false positive rate.
In AdTech, AI is revolutionizing creative management, allowing advertisers to dynamically generate personalized content variations based on known audience data. By incorporating an AI model, Ad-Lib (developed in partnership with Xenoss) reduced the creative production speed by 75% and slashed the creative production costs for its users by 2.5X.
If you’re unsure about the optimal use cases, talk to technology advisory firms to better
understand the state of play in your market. Doing a discovery session with an experienced AI team can help bridge the gap between problem identification and AI implementation.
2. Analyze your data estate
AI models require ample data for training and validation to produce accurate results. Large language models (LLMs) like ChatGPT, for example, need anywhere between 570GB to 45TB of training data.
Generally, you need at least 10X as many data observations as the number of features in a dataset to train a viable machine learning model.
Respectively, you need to first determine if you have enough data to pursue the selected use case(s). Do a data discovery session to determine which data is available and how it can be used for AI application development.
Global data privacy laws and industry regulations restrict the usage of sensitive information for analytics purposes. So, not all available assets may be used unless you apply privacy-preserving techniques like data aggregation and anonymization, homomorphic encryption, or federated learning.
Alternative approaches to data acquisition for AI include:
- Usage of public, open-source datasets for model training. Plenty of research institutions, non-profit, and commercial organizations share pre-cleansed, anonymized datasets for model training.
- Data enrichment. To increase the size of your dataset, consider joining forces with other businesses in your industry. For example, Mastercard, together with 9 UK banks, including Lloyds Bank, Halifax, Bank of Scotland, NatWest, Monzo, and TSB, created a large-scale payment dataset for training fraud detection models.
- Synthetic data. You can use computer-generated datasets for securely training models on mock data. Researchers agree that synthetic datasets can increase privacy and representation in AI, especially in sensitive industries like healthcare or finance. Gartner predicts that by 2024, as much as 60% of data for AI will be synthetic.
All the acquired training data will then have to be pre-cleansed and cataloged. Use consistent taxonomy to establish clear data lineage and then monitor how different users and systems use the supplied data.
To further increase the quality of your datasets, run an exploratory data analysis to better understand the distribution, potential outliers, and relationships between variables. Doing so helps identify potential inconsistencies or under-representation, which can then affect the model’s accuracy. If that’s the case, consider data enrichment or synthetic data generation.
3. Organize and prepare training data
Acquiring data is just one step in the AI project lifecycle. Ongoing data engineering is a much more complex process.
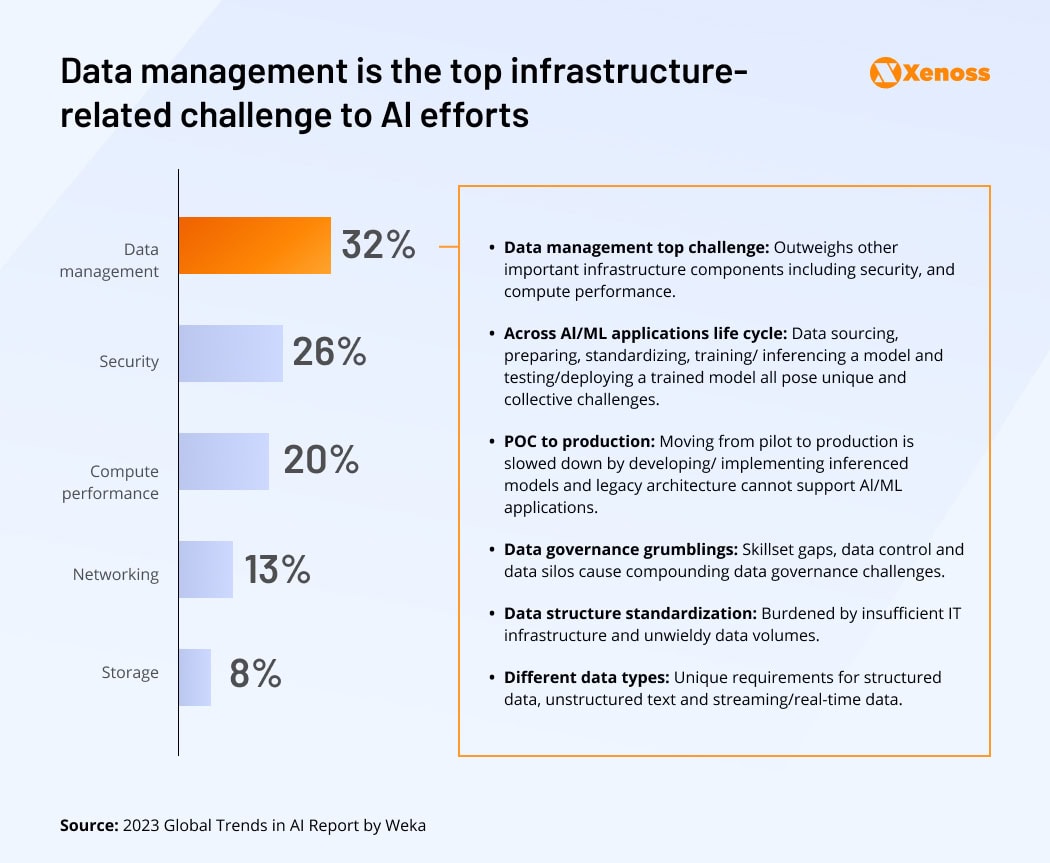
Depending on the use case, AI models require ample structured and unstructured data. Most companies (66%) surveyed by Weka use structured data from database management systems. Half also includes streaming data from sources like IoT devices, online transactional systems, traffic systems, or web server logs. Structured and semi-structured data types require less data processing, meaning they can be made available to AI systems faster and at a lower cost.
Unstructured data like images, spoken texts, or audio are also being actively used for model training, especially in computer vision and generative AI (artificial intelligence) projects. However, this data class needs more transformation—cleansing, normalization, and pre-processing—to become suitable for model training. In addition, you’ll have to divide available data into training, validation, and test datasets to benchmark the developed model.
Mature AI development teams complete most of the data management processes with data pipelines — an automated sequence of steps for data ingestion, processing, storage, and subsequent access by AI models.
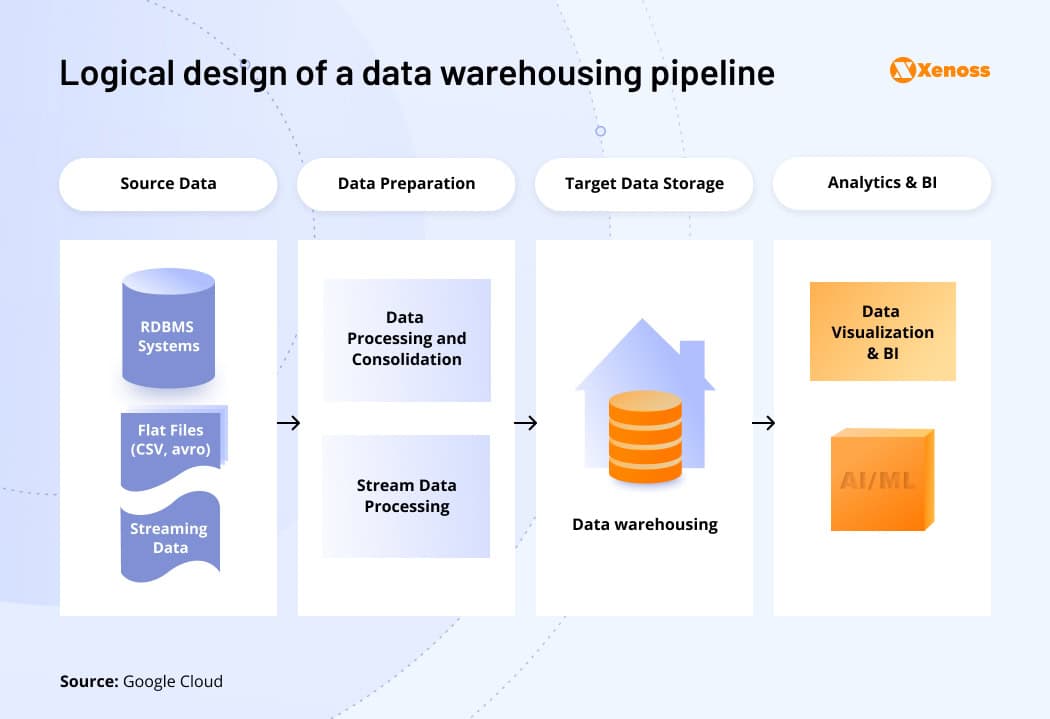
With a robust data pipeline architecture, companies can process millions of data records in milliseconds in near real-time. The Trade Desk, for example, can process over 800 billion queries per day in near real-time with a data architecture based on Aerospike and AWS. Amazon’s Supply Chain Finance Analytics team, in turn, optimized its data engineering workloads with Dremio. With the current setup, the company set new extract transform load (ETL) workloads 90% faster, while query speed increased by 10X. This, in turn, made data more accessible for thousands of concurrent users and machine learning projects.
4. Determining the optimal model algorithm(s)
Modeling is the next step in the AI project cycle. Generally, all AI systems are based on either machine learning, deep learning, or foundation (generative) models. These, in turn, can be created using different algorithmic approaches. Your use case(s) and data availability will dictate the optimal algorithm method.

Supervised machine learning algorithms can be used to solve a wide range of analytical problems that require predictions or classifications based on available data. They are relatively easy to engineer, and they require fewer computing resources for training.
On the downside, supervised machine learning requires ample labeled training data. Also, such models aren’t suitable for ad hoc data analysis, where you’re trying to identify potential correlations and patterns in a large data set (e.g., identify the drivers for higher product sales).
Unsupervised machine learning systems can discover new patterns in high volumes of data, even when the datasets have outliers or other types of “noise.” Because unsupervised algorithms can be trained on both labeled and unlabeled data, you can also explore more use cases.
Unsupervised machine learning techniques, however, result in greater algorithm complexity and poorer interpretability. Depending on the algorithm, hyperparameters, and preprocessing steps, model results can be subjective and hard to verify. It’s also harder to verify the accuracy of clustering or pattern discovery as there’s no labeled data.
Reinforcement learning supports some of the most advanced AI applications, like autonomous driving and advanced robotics. With RL, algorithms learn from scratch through trial and error, which leads to results beyond human performance. Yet, RL systems are data and computation-intensive. The training process is complex, too, and prone to issues like sample efficiency, stability of training, and catastrophic interference problems, among others. Successful commercial applications are still few and mostly come from Deep Tech companies.
Foundation models are the backbone of generative AI. By using a pre-trained, fine-tuned model, you can rapidly train a new-gen AI algorithm. Usually, foundation models require less maintenance once deployed since they’re robust and adaptable by design. Unlike traditional ML frameworks for natural language processing, foundation models require smaller labeled datasets as they already have embedded knowledge during pre-training.
That said, foundation models can still produce inaccurate and inconsistent outputs. Particularly when applied to domains or tasks that differ from their training data. Training a foundation model from scratch also requires massive computational resources. When deployed in production, large-scale models also require optimized IT infrastructure to run effectively, which further increases their operating costs.
Our best advice on how to program an AI application? Work from your use case and analytical problem to find the optimal algorithm. As you evaluate different AI frameworks consider factors like accuracy, interpretability, and computational cost.
5. Begin model training and validation
Model training is arguably the most important step in the implementation framework of an AI process. That’s when you learn whether the selected algorithm and allocated data can be used to solve your use case.
Common challenges of AI model training include:
- Training-serving skew occurs when model training conditions differ from deployment conditions. Effectively, the model doesn’t produce the desired results in the target environment due to differences in parameters or configurations.
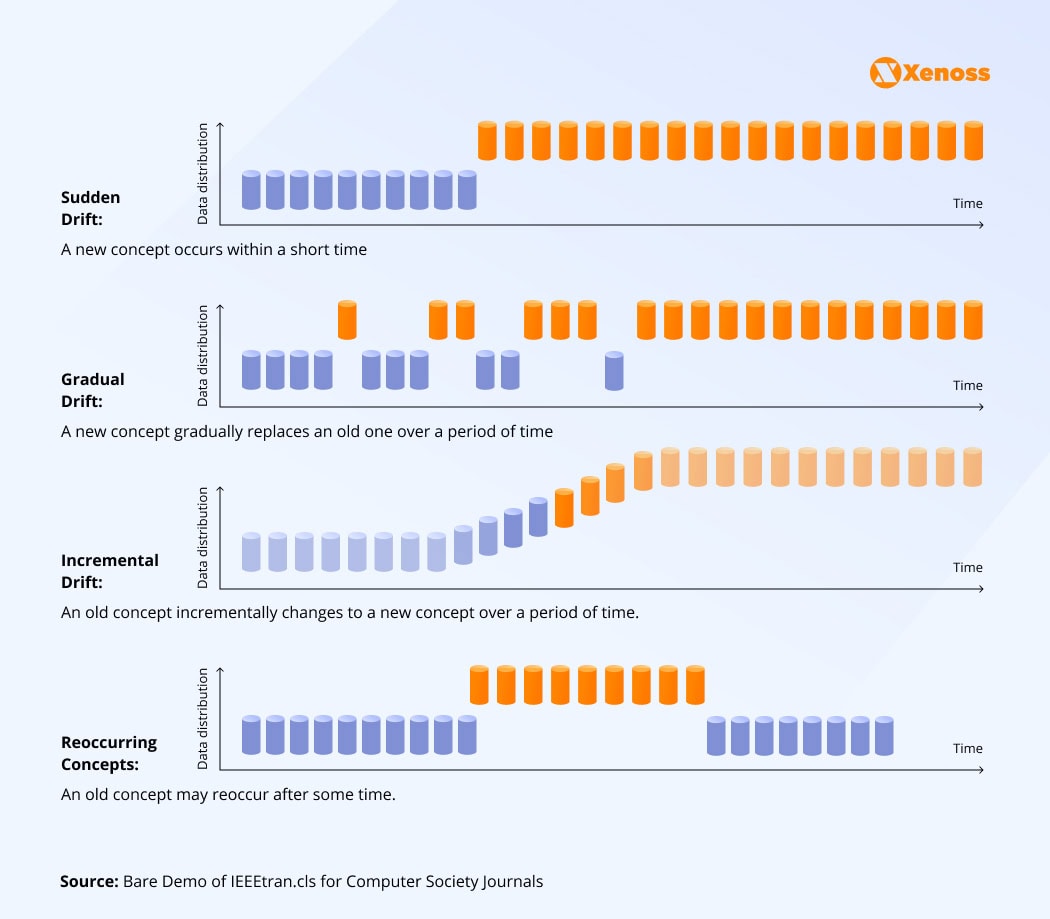
- Data drift occurs when the statistical properties of the input data change over time, affecting the model’s performance. For example, if the model dynamically optimizes prices based on the total number of orders and conversion rates, but these parameters significantly change over time, it will no longer provide accurate suggestions.
- Concept drift occurs when there’s a mismatch between the training data and the actual data you’re feeding to the model. For example, a threat intelligence model was trained to detect specific malware classes. If a novel malware type emerges, it may no longer accurately detect it.
In most cases, AI developers produce several versions of the same model to validate different approaches and fine-tune its performance. Few teams immediately develop a deployable model. Instead, most maintain a database of model versions and perform interactive model training to progressively improve the quality of the final product. On average, AI developers shelf about 80% of produced models, and only 11% are successfully deployed to production.
Hyperparameter tuning is one of the essential techniques for training better AI models. Effectively, you train separate versions of the same model, each with a different set of hyperparameters (e.g., learning rate, number of estimators, type of regularization, etc). Then, you benchmark the interactions to identify the model version with the highest accuracy.
Feature engineering is another important practice. A model with too few features struggles to adapt to variations in the data, while too many features can lead to overfitting and worse generalization. Highly correlated features can also cause overfitting and degrade explainability approaches. A good practice is to use SHAP values to identify how each feature contributes to the model output and remove correlated, redundant, or uninformative features.
If you’re still concerned about model accuracy, run another data quality check. Verify for outliers and inconsistencies in your dataset. Verify consistent data schema application.
Great Expectations is a helpful free tool for checking assumptions about data. Pydantic is an effective AI library for defining data models in Python. Realized you have too little data for model training or retraining? Consider generating extra synthetic samples or trying the Active Learning method.
6. Prepare for model deployment
Model deployment to production is the final step of an AI project cycle. But it’s also the most error-prone one. Only 32% of ML projects–including refreshing models for existing deployments–typically reach deployment.
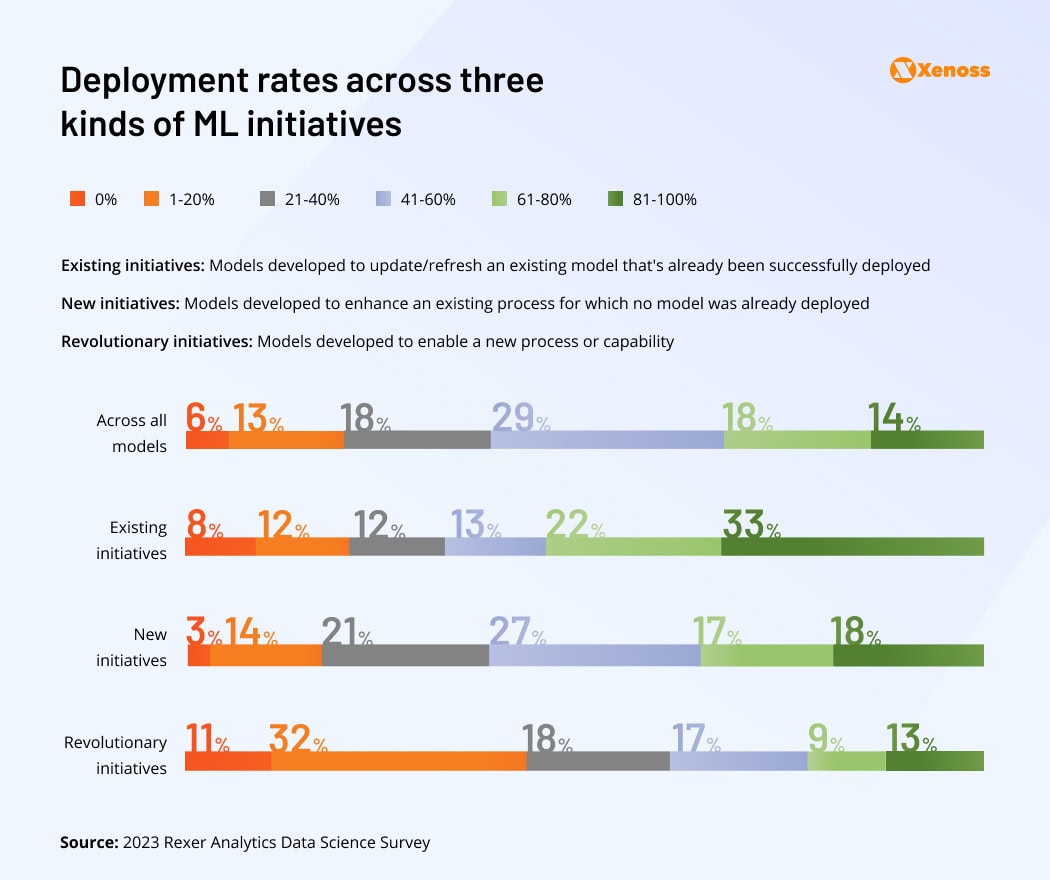
The reasons for failed deployments vary from lack of executive support for the project due to unclear ROI to technical difficulties with ensuring stable model operations under increased loads.
A former Netflix engineer talked about the challenges the team faced when deploying the platform’s content recommendation system. The team needed to ensure that the ML model was highly available and served highly personalized recommendations from the titles available on the user device — and do so for the platform’s millions of users.
To ensure high performance, the team decided to program model scoring offline and then serve the results once the user logs into their device. The type of production environment configuration reduced latency because the model outputs were not dependent on highly available servers running the recommendation services at scale for each user. It also helped the company optimize cloud infrastructure costs.
Ultimately, successful AI model deployments boil down to having effective processes. Just like DevOps principles of continuous integration (CI) and continuous delivery (CD) improve the deployment of regular software, MLOps increases the speed, efficiency, and predictability of AI model deployments.
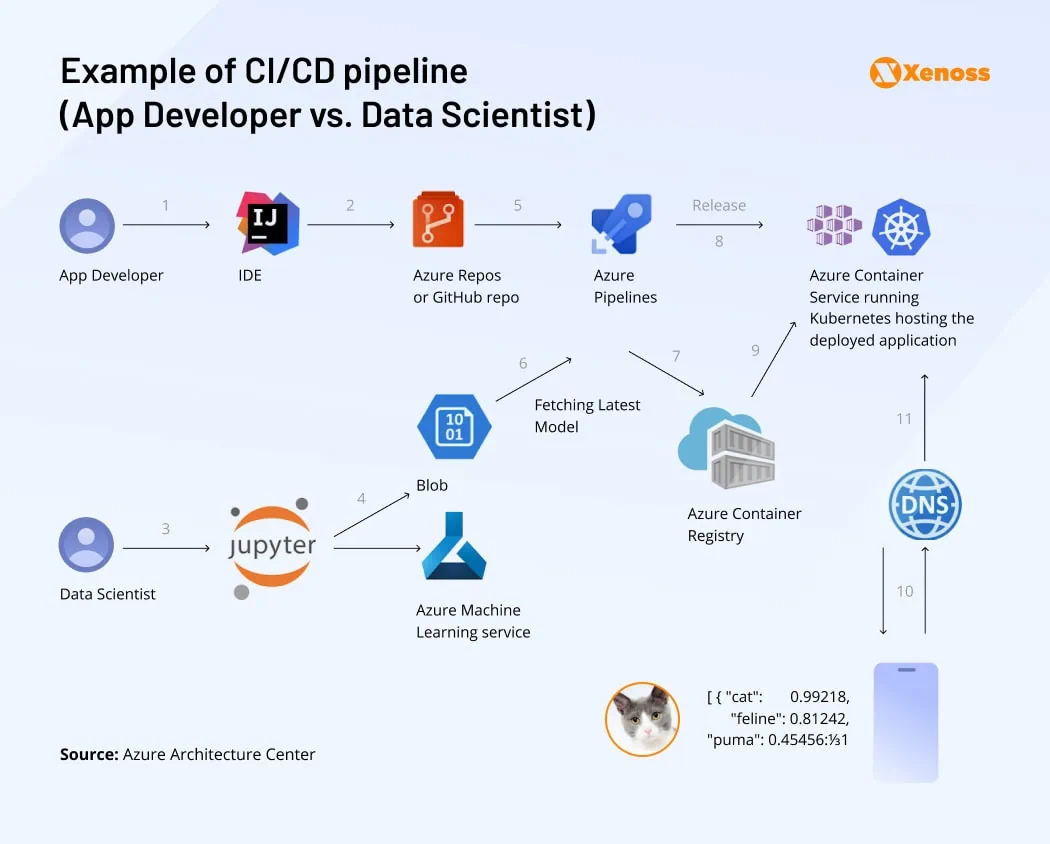
MLOps borrows DevOps’ best practices, such as pipeline automation, version control, and continuous testing, and adapts them to the new realities of deploying AI models. The key practices involve:
- Seamless data serving and transformation from connected sources
- Automated pipelines for model training and testing
- Implementation of a centralized experiment tracking system
- Automated replication and version control of models
- Unified governance and management for all produced models
- Containerized model deployment workflows
- Introduction of data-backed feedback loops
Model feedback loops help AI developers better understand model performance in real-world settings. These should include both technical metrics (e.g., accuracy, recall rates) and business metrics (e.g., ROI or user engagement) to further secure support for the project(s).
By applying MLOps principles, your teams don’t have to wonder how to get AI to production. Instead, they can focus on optimizing model performance and iterating on more advanced model versions.
How to choose the right AI development tools for your project
Apart from being a cultural shift, MLOps also encompasses a large universe of AI development tools, ranging from cloud services for AI projects from major CSPs to open-source ML frameworks, created by leading research institutions (e.g., Caffe, Keras, Theano).
A standard AI development toolkit includes:
- Preferred ML/DL/RL/Gen AI frameworks and libraries
- Data labeling and annotation services
- Data streaming and data pipeline management tools
- Model catalog, versioning, and testing environment
- Feature engineering solutions
- Model monitoring and governance tools
- Cloud and distributed computing resources
- Security, privacy, and explainability apps
When choosing the right AI development tools for your project, it’s essential to consider the human element. Pankaj Rajan, co-founder of MarkovML, highlights a significant shift in the ML space.

The Linux Foundation maintains an interactive list of the top AI tools, which you can segment by features, license type, and software vendor, among other parameters.

AI development teams typically choose between building a custom MLOps platform (by combining the best AI software into an integrated developer environment) or using different commercial AI platforms, pre-furnished with different AI developer tools (e.g., Amazon SageMaker, Google Cloud Vertex AI, Azure Machine Learning platform, etc).
Whether you’re assessing a commercial offering or building your toolchain, invest in the following MLOps platform capabilities:
- Data management and pre-preprocessing. Build repeatable workflows for data ingestion, storage, and preprocessing. Look into solutions that facilitate data labeling, data versioning, and data augmentation/enrichment. Make sure your platform integrates with the used data storage systems (e.g., MongoDB, Redis, PostgreSQL, etc).
- Experimentation and model development. You’ll need a collaborative space for storing experiment data, monitoring ongoing experiments, and performing model validation. Prioritize features like hyperparameter tuning, feature engineering, automated model selection, and model performance analytics for easier debugging.
- Pre-installed frameworks and libraries. Popular MLOps platforms include a roster of open-source AI frameworks (TensorFlow, PyTorch, H20) and AutoML tools for faster model creation. Verify that you can easily bring extra libraries and integrate more tools to support a wider range of projects.
- A model registry is a virtual storage space for production-ready AI solutions. It should have data on model type, key artifacts, features, and creation time, plus store training parameters and hyperparameters associated with it for easier benchmarking.
- Model deployment pipelines. Features like containerization, API management, and scalable serving infrastructure add predictability to model deployments.
- Model monitoring tools and dashboards help key performance metrics (e.g., accuracy, precision, recall) to detect performance anomalies, identify data or concept drift, and activate model retraining when needed.
- Orchestration tools help automate pipelines and streamline workflow execution. Look for solutions that facilitate workload dependency management, task scheduling, and error handling to simplify the management of complex ML workflows.
- Model governance tools help incorporate ethical considerations, privacy safeguards, and regulatory compliance into your AI solution. These also often include explainability and anti-bias solutions.

Key takeaways
The answer to the question of how to make an AI system boils down to following a sequence of steps: Determine the analytical problem, analyze available data, prepare training and validation datasets, select the optimal algorithm, do interactive model training, and, finally, securely deploy your model to a production environment.
MLOps practices and tools substantially increase the speed, predictability, and quality of AI application development, plus help you get objective data on model performance to justify further investments.
Remember: This year, more businesses plan to bank on AI as a driver for business growth. The first to cross the finishing line will get all the advantages of being the first mover — higher market share, stronger brand recognition, and customer loyalty.


