Imagine setting up a test project with a billing budget of $7, a free database plan on the Google Cloud Platform and spending $72,000 overnight. A startup founder received a massive bill due to a mistake in configuring the Firestore NoSQL database deployment: The database made 116 billion reads and 33 million writes to Firestore. The project team was on the edge of bankruptcy without even going live with their MVP.
Luckily, after reviewing the incident, Google didn’t charge the startup for the services. But happy endings such as this are exceptions. Wrong tech stack or architecture choices lead to unbearably high costs of technology that can even burn the business to the ground.
In this article, we’ll talk about:
- Common mistakes teams make when selecting tech stack and an architectural approach for data-intensive AdTech applications
- How to avoid them and design a scalable and cost-effective system
To better understand how a suboptimal tech stack and a system architecture lead to scalability limitations and a high infrastructure bill, we’ll explore how Xenoss redeveloped a client’s product to lower operational costs.
Short videos from the joint webinar with Xenoss CTO Vova Kyrychenko and Aerospike’s Global Director of AdTech and Gaming Daniel Landsman will give more context to our discussion.
Vladyslav Kushka, Delivery Manager at Xenoss, also joined the conversation. Relying on his two-decade experience in software engineering and technical management, Vlad shared tips on selecting an appropriate tech stack for data-intensive AdTech solutions, particularly a codebase and a database. So let’s begin.
Xenoss in action: Infrastructure cost optimization for an AdTech client
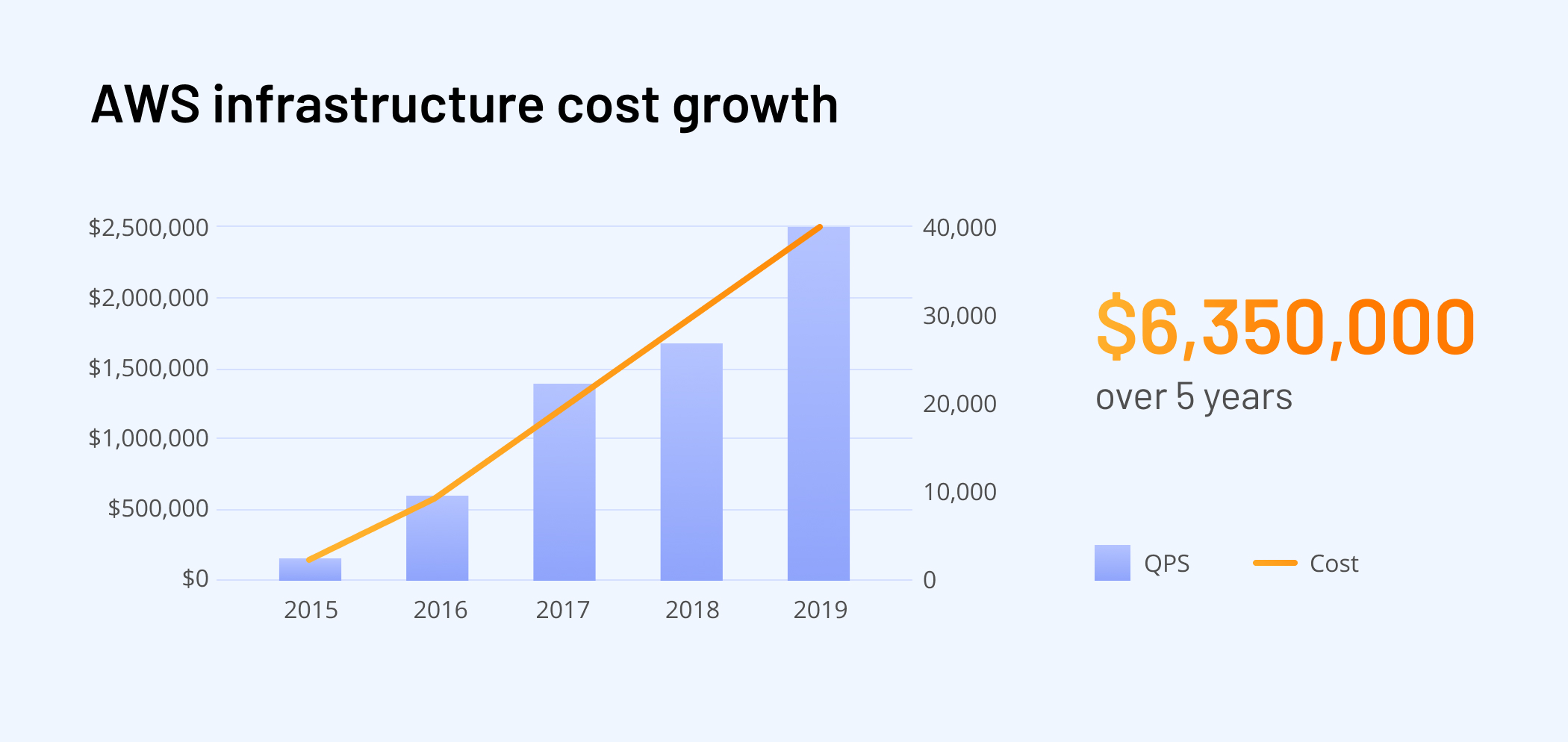
Poor architectural decision-making is one of the reasons for skyrocketing infrastructure costs. The case from our practice is a solid example. An AdTech company with a proprietary DSP reached out to Xenoss with a request to help them reduce surging AWS costs that were squeezing profit margins and getting in the way of the business growth.
The client rolled out the system in 2015. By 2016, the bill shot up to $500,000 a year; by 2019, the company was shelling out $2,500,000 a year. Overall, the cost was $6,350,000 for AWS cloud computing over five years.
The team faced enormous operational costs because of poor infrastructure optimization and suboptimally chosen technologies for the system. The demand-side platform’s tech stack was Node.js, PHP, Go, MySQL, and MongoDB, along with six load balancers from Amazon that distributed traffic across 450 front servers supported by 150 Mongo servers.
The Xenoss team defined the system’s weak spots and updated its architecture in three steps: redesigned cloud architecture, adapted for real-time, with reorganized data pipelines.
Changes to cloud architecture
The first step for reducing IT infrastructure costs is to revise the shared-economy services the high-load system relies on and replace them with self-service solutions. For instance, AWS Lambda users are charged based on the number of requests for their functions and how long it takes for code to execute. While 100 requests per second may cost less than $100 monthly, a bill for processing 300,000 requests per second may exceed $150,000. You end up paying more for the shared hardware than if you manage it yourself.
To reduce a cloud bill, the team eliminated shared-economy services, stopped billable data-transfer services (Kinesis, Firehouse), and improved load-balancing.
Reengineering architecture for real-time
Xenoss revamped the architecture so it no longer relied on Amazon APIs. The team also replaced Node.js with Java to adjust the system for real-time as it provided a much more resilient environment for handling thousands of queries per second and (maintaining the system performance amid) traffic fluctuations.
Also, our architects substituted the data model that required MongoDB servers with Aerospike’s node-local in-memory storage for real-time access. As a result of this decision, server performance substantially increased, which allowed using only 10 servers instead of 450 while doubling the traffic. Additionally, specialists implemented an effective, scalable in-memory search with K-D indexing.
Reorganizing data pipelines
We reengineered the data pipeline to exclude data transfer and access redundancies. As part of this process, data was written and read only once for intermediate operations, resulting in a significant reduction in data storage and access costs. This, in turn, enabled more advanced data compression and warehousing options.
Let’s summarize. To make the DSP’s infrastructure more cost-effective, the team:
- Reengineered the data pipeline
- Built a cloud-neutral architecture
- Eliminated expensive managed cloud services
- Introduced an in-memory search for fast and effective use of real-time data
As a result of these actions, annual infrastructure costs decreased from $2,500,000 to $144,000.

Most common mistakes when designing a high-load architecture
Several problems with the architectural design cause infrastructure cost mismanagement. Let’s dive in.
Lack of experience in building high-performance systems
At a product’s early stage, infrastructural costs mainly comprise 5% or 10%. Therefore, a product team may assume that strengthening an engineering team with specialists experienced in designing high-load applications is more expensive than adopting managed cloud services that solve most architecture problems.
Once a business starts scaling and the cloud computing bill swells, it can become 80% of operational costs – exceeding a team cost.
This is an excerpt from the webinar with Xenoss CTO Vova Kyrychenko hosted by Aerospike. Follow the link to watch the event in full.
Solution: Hire software engineers who can build data-intensive applications, monitor and test their performance and suggest improvements if needed, predict database scaling patterns, optimize systems to minimize downtime, and cut costs.
Using a backend codebase that isn’t optimal for high-load solutions
“The backend of high-load big data platforms is usually responsible for up to 90% of operational expenses. In this case, the codebase choice can significantly influence the financial footprint as applications written in different programming languages use different amounts of CPU and memory resources,” notes Xenoss’ Delivery Director Vladyslav Kushka.

It’s especially relevant to cloud-based applications because providers turn any performance criterion into a billable one. Product teams that select a language that isn’t resource-efficient amid increased load end up receiving enormous infrastructure bills.
Advice: In such a situation, one can consider substituting a tech stack, particularly a codebase, with one that will allow a solution’s backend to operate more efficiently, performing as many operations as possible in less time while consuming less CPU and memory.
We mentioned earlier that, in one of the projects, the Xenoss team ported the backend codebase in a client’s application from Node.js to Java. Their goal was to cut infrastructure costs for an AdTech solution by revamping its architecture. The system was designed to process large amounts of data and rapidly perform complex calculations, so scalability and cost-efficiency were critical.
As a compiled language, Java is very effective in CPU usage. Thanks to Java’s multithreading capabilities, it handles concurrent requests more efficiently than single-threaded Node.js. That’s why using Java for data-intensive applications is feasible.
The more critical the infrastructure cost issue becomes, the greater role the language’s advantages play, and the more obvious choice in favor of Java for a backend of a high-load solution becomes.
“Similarly, a backend of ad exchange can be written in Python during prototyping. Still, once the product reaches the scaling phase, this codebase will have to be replaced with a more optimal one in terms of performance and resource use, for instance, with Golang, Java, or Rust,” notes Vladyslav.
Suboptimal choice of cloud-native solutions
A widespread mistake is choosing a cloud tool with pay-as-you-go pricing without keeping in mind the increase in an application’s load. In this case, cloud service bills may take customers by surprise.
When talking about cloud sticker shock, Lenley Hensarling, Chief Strategy Officer of Aerospike, noted that adopters generally don’t estimate service bills when a product is scaling: “I think people experience sticker shock in multiple ways. The chief one when they go in and tend to think ‘This looks almost free.’ It’s a low cost to get in for the initial bite, but then they start learning things like how many transactions they’re executing per second, and there’s the cost for every of those.”
During the webinar, Vova Kyrychenko mentioned DynamoDB on AWS or Google’s BigQuery, each of which charge for every access to data, so user spending directly depends on the number of requests.
It’s no wonder that database management services like Amazon RDS, DynamoDB, or Google BigQuery permit users to estimate the cost of executing a query.
Solution: Meticulously review available cloud services (data analytics and storage) and their pricing models to choose the ones that work best for you in terms of the business’ budget and scale strategy.
If your technology deals with high-traffic loads or involves computation-intensive processes, consider services whose cost isn’t tied to the number of requests to a database, such as Aerospike or ClickHouse.
Taking management into your own hands with self-service solutions is another way to avoid overspending, as they allow for optimizing database performance, particularly data querying. To adopt self-service tools, a company must have DevOps expertise.
DevOps specialists will choose tools that work best for the system and ensure the transition from managed cloud to self-service cloud solutions is smooth, as they have the expertise to design, implement, and manage the infrastructure needed to run applications on the cloud. In particular, they can automate cloud solutions’ provisioning and deployment, set up monitoring and logging tools to ensure the infrastructure works as intended, or maintain its security.
Selecting a DBMS that isn’t optimal for a solution’s data model
Data architecture, which defines how data is stored, managed, processed, and shared within an organization and across different systems and applications, is as important as code architecture. The incorrect choice of a database management system for a high-load system can lead to issues working with data once the workload grows. A product team may face insufficient speed of operations, such as data location, retrieval, or analysis. Consequently, the application would need to rely on extra servers to meet performance requirements, costing more to maintain.
Advice: Pick a data management system based on data types a business deals with and data use patterns. For instance, DynamoDB or InfluxDB can handle time-series data well; Aerospike, Redis, and Memcached are suitable for working with frequently accessed data (e.g., currency exchange rates, phone codes, audience tags, results of database calls). Document-oriented MongoDB can be a system of choice when managing configuration data, while MySQL can handle billing and accounting information well.
We have a dedicated article on selecting a database management system for AdTech projects, so read it to learn how to pick a database that will best suit your project. read it to learn how to pick a database that will best suit your project.
Not treating free cloud credits as real money
Cloud providers cover expenses on their computing services for startups. Google, for example, covers up to $100,000 in cloud credits for each of the first two years within the Google for Startups Cloud Program, up to $250,000 in credits for their first year, and up to $100,000 during the second for AI startups. Microsoft’s Azure gives up to $150,000 in credits for those it accepts into its Startups Founders Hub, while startups that want to build on AWS can apply for up to $100,000.
While cloud credits can be a great way to get started quickly and avoid high upfront costs, they can create a false sense of security when it comes to the ongoing costs of running a business. Tech companies that neglect cost optimization during the infrastructure design risk not keeping up with operational costs once credits expire.
Advice: Carefully monitor infrastructure usage and estimate future spending. If you forecast that operational expenses will grow too high for you to sustain profits, devise a strategy for optimizing infrastructure. You can contact a tech partner for consultation if your team doesn’t have sufficient expertise on the matter.
How to choose the right stack and architecture
Scalable and cost-effective architecture is every product team’s dream. Let’s overview the factors you should consider to design an AdTech system that is ready for growth and affordable to manage.
When selecting a tech stack, think about your budget, team DevOps expertise, the amount of data you expect to deal with, and the performance requirements. You need to upload a vast amount of data, adjust indexes and compression, and see how the solution operates. The best architecture solution is the result of tests and experiments.
Moreover, you need a tech stack with flexible optimization options to configure the application when your needs change. For instance, our engineers developed many solutions using Aerospike, as their in-memory database allows for delivering efficient, low-cost infrastructure to clients.
The final word
The commercial success of a tech company largely depends on the choice of tech stack for its high-load product. Professionals with experience in developing and maintaining data-intensive applications can pick an optimal tech stack based on estimates of how a business will grow in one, two, or five years. At the same time, AdTech companies that did find themselves strangling in surging infrastructure costs can reach out to a tech partner that will conduct a technical audit and revamp a solution.


