AdTech products’ success rates are predicated on the efficient collection and use of big data, but more importantly, on how it is stored, processed, and analyzed.
Advertising platforms must deliver multi-dimensional insights on real-time and historical campaign performance. To follow the industry trends in omnichannel ad attribution and cross-platform customer profiles, there’s a lot of data that AdTech companies need to store, move, and process every minute.
Consequently, adopting a flexible database management solution (DBMS) is a must.
In this post, we discuss:
- What a database management system is and its role in data warehousing
- Common types of DBMS with an in-depth OLTP vs. OLAP comparison
- Redshift AWS, Google BigQuerry, and ClickHouse as top DBMS options for AdTech
What is a database management system (DBMS)?
A database management system (DBMS) is a software package designed to facilitate data retrieval, manipulation, and management in a centralized database.
A DBMS provides a “template” for organizing all the aggregated data by type, format, or another parameter. It also serves as an interface between the data storage tier (e.g., distributed data store) and the software application consuming the data (e.g., your DSP or SSP).
A DBMS is one of the central data warehousing concepts.
Common data models include:
- Relational structures
- Non-relational structures
- Geospatial structures
- Time series structures
Apart from structuring data, DBMSs also provide extra database administration capabilities for managing computer resources, optimizing database performance, establishing a data governance process, and more.
According to Gartner, a DMBS reflects optimization strategies designed to support database transactions and/or analytical processing for one or more of the following use cases:
- Traditional and augmented transaction processing
- Traditional and logical data warehouse
- Data science exploration/deep learning
- Stream/event processing
- Operational intelligence
In other words: a DBMS is sort of a “wizard” app for organizing your data in neat virtual stacks, be it in a data warehouse (DWH), a data lake, or any other type of data warehousing structure.
What does data warehousing allow organizations to achieve?
Data warehousing helps locate, centralize, and maintain large amounts of data from multiple sources in a readily-accessible state. Consolidated, pre-cleansed, and (often) anonymized data sets from the warehouse can then be used to:
- Generate reports with self-service BI tools
- Perform anything-by-anything styled queries
- Deploy predictive, ML-driven analytics models
- Create custom real-time reports and visualizations
Modern DWH platforms also help organizations:
- Improve data provisioning from multiple channels (with low latency)
- Optimize database performance and operating costs
- Implement proper data security controls
- Streamline data governance
In short, data warehousing helps maximize the value of available data while ensuring its security and compliant processing.
Types of database management systems
There are five main types of database management systems:
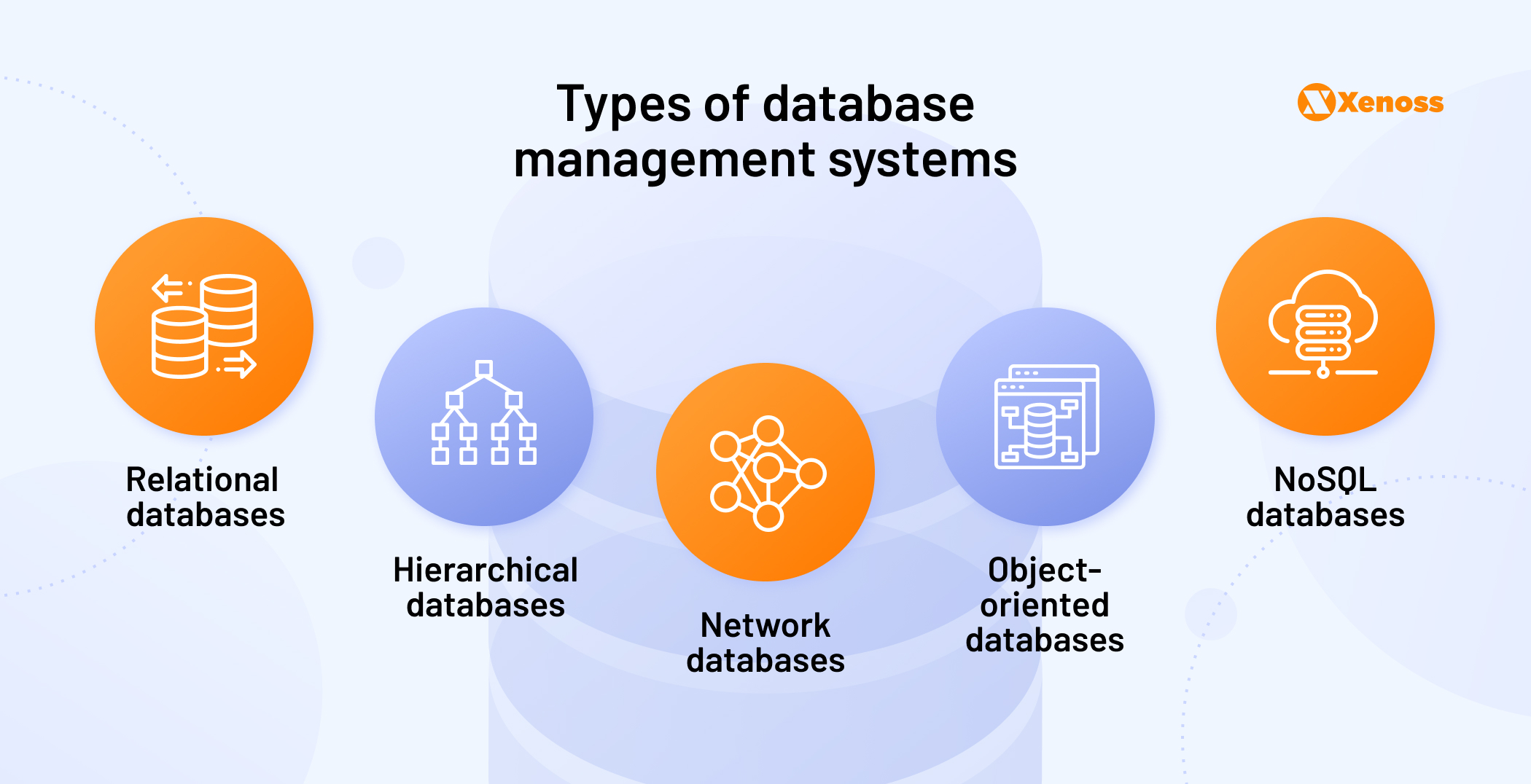
Relational databases store data in bi-dimensional tables consisting of rows and columns. These tables indicate how different data points are related to one another (hence the name). This structure allows accessing data in many different ways without reorganizing the database tables themselves. Because of this, relational databases offer faster querying and can support different analytics use cases.
Hierarchical databases use a parent-child structure, where each “parent” data directory contains links to lower-level subdirectory branches, which, in turn, can contain even more subdirectory branches (or child records). One child directory can only have one parent directory. Data records contain data as fields, where one field can only contain one value. To access data, you must traverse the entire hierarchy to access a specific root node. For bigger databases, this slows down querying.
Network databases also establish relationships between different records, but rely on a graph structure. In this case, one record can have multiple owners (parents) and thus provide multiple paths to access the data.
For AdTech companies, hierarchical and network databases aren’t a great choice because of:
- Rigid data structures inherent in their design
- Complex system design
- Lack of structural independence between data records
Object-oriented databases and NoSQL databases have slightly different methodologies for data storage.
These are designed to store data objects rather than primitive data entries. Primitive data types are characters, text strings, numbers, and hashes. Data objects, in turn, can contain more complex values or groups of values such as tables, arrays, records, etc.
Object-oriented databases (OODs) treat all relational database values (tables, rows, columns) as objects by default. In contrast, developers need to create an object from the results of a set of queries for relational databases. There’s different mechanics for codifying data in OODs, which makes them more suitable for apps written in object-oriented programming languages like Java, Kotlin, C#, or Swift.
For AdTech projects, OODs aren’t always the optimal choice because of the lack of persistence compared to relational systems. Also, such databases are more prone to performance issues when the system becomes complex.
NoSQL databases are best for storing unstructured data — information that doesn’t fit into a preset data model or schema and therefore can’t be stored in a relational database.
A NoSQL DBMS is a better choice for building data lakes over data warehouses. You can keep records in a (semi-) organized state and do explorative querying. Then surface some relevant data to transfer it into a DWH for faster, easier access by BI tools.
Since NoSQL databases also allow horizontal scaling, they are more cost-effective than relational (SQL-based) solutions.
That said, there’re cases when going SQL vs. NoSQL makes sense.
Which DBMS is best suited for AdTech projects?
Relational database management systems (RDBMSs) are best suited for AdTech projects due to their ability to support multiple column-based tables of data records and run multidimensional analytics.
Innovative AdTech startups need to provide accurate data on user attribution (e.g., user ID, device, OS, etc.) to accurately report on generated impressions. Relational databases allow correlating data points across different dimensions and rapidly deliver accurate multidimensional reporting.
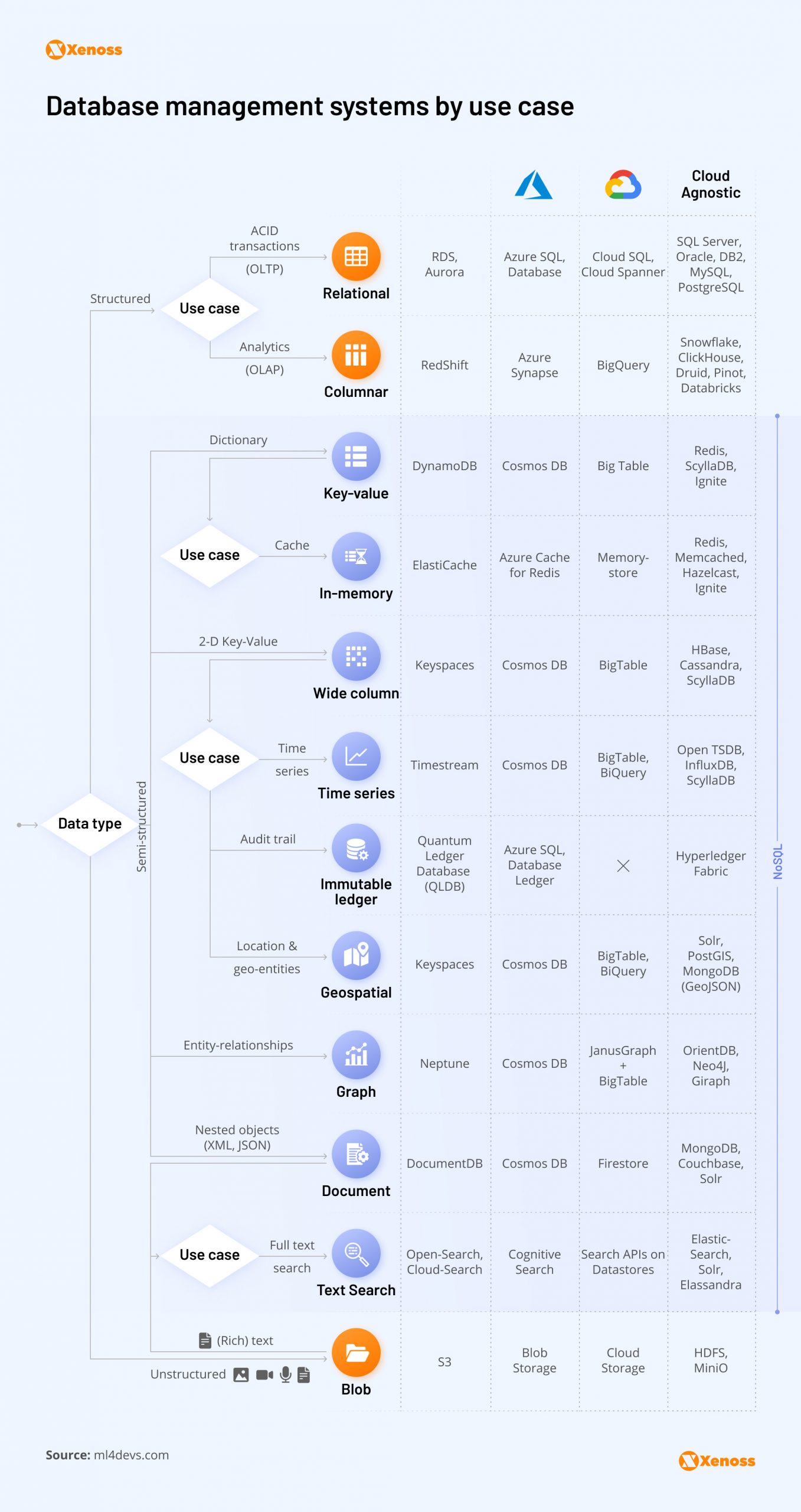
In the context of RDBMS, there are two main types of databases: online analytical processing (OLAP) and online transaction processing (OLTP).
OLTP vs. OLAP databases: Comparison
Depending on the underlying technical characteristics, relational database management systems fall into two categories — OLTP and OLAP.
What is OLTP?
An online transaction processing system (OLTP) can execute multiple financial transactions simultaneously, such as online banking, shopping, order entry, or texting, and captures all associated records for storage.
The defining characteristic of OLTP database transactions is its atomicity — a transaction is either fully successful or fails (or is canceled) completely. It cannot remain in a pending state. The above renders transactional databases highly effective for financial processing, especially for companies that need to support many transactional changes, write-offs, payments, and fine-grained queries.
However, OLTP was primarily designed to handle simple, concurrent data queries, so they’re rarely applied anywhere outside of the financial domain.
OLTP DBMS:
What is OLAP?
An online analytical processing (OLAP) system extracts data from multiple relational datasets and reorganizes it into a multidimensional format. OLAP is the go-to approach for structuring massive databases with infrequent changes in underlying design (i.e., the types of collected data points are the same).
The core element of every OLAP database is an OLAP cube — a multidimensional environment for organizing big data. It allows you to rapidly locate, access, and analyze similar elements within a particular dataset.
OLAP data processing engines, in turn, are fine-tuned for doing analytical processing tasks such as aggregation, filtration, or summarization to derive statistical information and reporting. Reports can be accelerated by using different paths for data queries.
In an OLTP vs. OLAP comparison for AdTech projects, OLAP systems win because they support column-based data storage — a “natural” fit for the type of reporting AdTech platforms provide.
Building record-type systems in OLTP is extremely cumbersome. For example, if you were to use OLTP for aggregating all available data by device, you’d have to extract all available records first, then select specific columns from which you’ll be extracting data.
In a column-based system, all the necessary data is auto-assigned to a designated column, so you’ll spend less time and computing resources on extraction and data analysis.
Remember: Data preparation can be a costly step. According to the State of Data Report by SnapLogic:
Nine out of 10 IT leaders experience challenges when trying to load data into data warehouses. The biggest hindrances are legacy technology, complex data types/formats, and data silos.
Separately, almost half (48%) of IT leaders agree that data stored in DWH still requires cleaning before being useful.
A properly designed and well-maintained OLAP database can reduce the costs and complexities of consolidating, cleaning, and maintaining data in a reporting-ready state.
OLAP DBMS:
AWS Redshift vs. Google BigQuery vs. ClickHouse
The DBMS software market has a growing number of closed-source (proprietary) and open-source players.
The open-source DBMS is dominated by non-relational database products (MySQL, Postgres, MongoDB).
The relational database market (and OLAP in particular) is now in the hands of hyperscale cloud players — Amazon, Google, Azure, and IBM (to a lesser extent). Most of them meshed DBMS software with cloud computing and cloud storage offers.
While there’s a strong appeal for using cloud-supplied DBMS solutions, our experience as an AdTech development partner taught us to think about cost and performance efficiency first.
Data load is a key consideration when selecting a DBMS for AdTech platforms.
If you’re designing database architecture for a relatively low-load AdTech project (for example, a data clean room), managed DBMS services can be helpful since they speed up data discovery and ETL jobs (processing and loading data) at a low cost.
However, once your platform faces bigger data loads, managed services can grow into a huge expense. Most charge users per request or per hour. For example, Redshift AWS bills $0.44 per DPU-Hour for each Apache Spark or Spark Streaming job. Those cents can add up fast.
In addition, you need to pay for cloud data storage, which is affordable and easy to provision. However, cloud elasticity is a double-edged sword: Your data warehousing costs can quickly spiral out of control without proper optimization.
Xenoss CTO Vova Kyrychenko dived deep into the topic, discussing real-life cases and solutions with Aerospike’s Daniel Landsman at the webinar “Architecting your database for scale and success.”
Take it from one unfortunate startup founder who woke up to a $72,000 overnight bill on the Google Cloud Platform (GCP). When setting up a test project, he didn’t properly configure his Google Firestore NoSQL database deployment. As a result, the cloud database made 116 billion reads, and 33 million writes to Firestore.
That said: Too rigid upscaling controls can undermine your database performance. You need to strike the right balance between costs and performance. We explain how to do that with different DBMSs.
Low-load AdTech projects: Choose AWS Redshift or Google BigQuery
BigQuery and RedShift are cloud-based DBMS products from Google and AWS, respectively. If you plan to take advantage of a platform’s robust BI and data analytics features, both are good choices.
Below we explain how each stack against five important criteria in DBMS selection:
- Manageability
- DevOps expertise
- Performance optimization
- Integrations
- Operating cost
Let’s dig in.
Manageability
Cloud DBMSs have one significant advantage: They offer managed services. Most database administration jobs are streamlined. You can also up/down-scale your deployments on demand or automatically.
Google BigQuery offers serverless infrastructure and convenient tools for resource self-provisioning. It also automatically provides replicated storage in multiple locations and high availability for no extra cost and with no additional setup. That’s helpful for ensuring low data processing latency.
With Cloud Dataflow, you can rapidly upload data to BigQuerry from across GCP cloud services like
- Cloud Bigtable
- Cloud Datastore
- Cloud Spanner
The tool auto-scales resources and ensures dynamic work rebalancing to minimize the processing cost per data record.
Apart from querying data stored at GCP, you can also access external data resources without any third-party tools. To create an integration, you’ll have to set up a Cloud Storage URI path to your external data and create a table that references the data source.
Redshift also offers serverless access to a DBMS where the company entirely manages your data warehouse infrastructure.
Separately, Redshift supports concurrency scaling — a feature that allows your databases to support thousands of concurrent users and concurrent queries without any performance losses. Query processing power is automatically added as concurrency. Once the demand subsides, extra processing power is removed.
The DBMS also monitors the health of your data clusters and auto-replicates data to ensure fault tolerance in the event of failed drives or nodes.
Another competitive feature is Automatic Table Optimization for all Redshift databases. The tool analyzes frequent workloads. Then automatically locates ways to improve data layout to optimize database querying speeds.
Redshift lets you run queries against pre-cleansed data from Amazon S3 buckets. Or you can use other AWS tools for extracting, transforming, and loading data to your Redshift database:
- AWS Glue
- Amazon Kinesis Data Firehose
- Amazon Redshift Data API
You can also find and subscribe to third-party data in AWS Data Exchange, then query it in Amazon Redshift within minutes.
DevOps expertise
Neither Redshift nor BigQuerry warrant having a flock of DevOps people on call to monitor data replication, cluster scaling, and data load (ETL) jobs.
A minimum requirement of Redshift is that administrators create clusters and nodes in the environment.
Redshift algorithms then do a good job with auto-scaling clusters, managing data storage, and data replication. You may be asked to approve occasional tasks, such as vacuuming tables based on suggestions from the Automatic Table Optimization service, but that’s about all.
BigQuery has an even more hands-free model. Google automatically handles all the infrastructure management tasks with auto-scaling happening in the background. As part of BigQuery’s focus on usability, users can do most tasks without relying on a database administrator.
Performance optimization
Since BigQuery and RedShift are cloud RDBMS solutions, you’re locked into relying on their suggested scaling paths.
Aside from implementing best practices, you can do little to accelerate BigQuery performance, since it determines the amount of resources (slots) it needs. That’s why you have to carefully monitor which data you ingest to avoid overspending.
Separately, you don’t have controls for optimizing data querying. For reference, a search index is a data structure designed to enable a more efficient search. Indexes are traditionally used for database performance optimization.
BigQuery doesn’t offer any secondary indexes. Redshift has no indexes at all. Redshift, however, supports the creation of unique, primary key and foreign key indexes (referred to in the Redshift Documentation as constraints). Yet, they are informational only and not enforced by Amazon Redshift.
Integrations
RedShift and BigQuery have native integrations with a variety of other analytics tools in their respective ecosystems. According to Gartner’s research:
The CSP products often add some special sauce that extends the community version – in their case, it’s cloud-native features that leverage their storage engines, their control of the stack, and increasingly their ability to share governance and even semantics with their other offerings.
For BigQuery, Google provides seamless integration with Data Studio — their prime offering for generating reports and data visualizations. The product also has convenient tools for data imports/exports (APIs and libraries) with detailed guides and setup instructions
Also, BigQuery integrates with:
Similarly, Redshift has native integration with other AWS services and pre-made connectors to third-party services via Amazon Redshift Partners directory.
Popular integrations include:
With pre-made integrations, you don’t have to figure out how to securely stick together your data from various locations or create custom workarounds for exporting data to other business systems or applications.
Cloud-native
Redshift and BigQuery are cloud-native products. You can’t deploy either of them outside of the respective cloud platforms (e.g., on your own hardware or in another cloud service).
For smaller projects, this is a definite advantage since you don’t have to face extensive database administration. Yet, for larger AdTech systems, the operating costs can eventually outweigh the convenience.
Costs
As of 2022, BigQuery costs $20/TB per month for the storage line and $5 per TB processed on that storage line.
RedShift pricing starts at $306 per TB per month for storage and unlimited processing on that storage.
A 2022 ECG report (commissioned by Google) notes that BigQuery can provide a three-year TCO that is up to 27% lower than AWS Redshift, Azure Synapse Analytics, and Snowflake. That’s a ballpark number, however, which may differ from one project to another.
High-load AdTech projects: ClickHouse
ClickHouse is a relatively new RDBMS that became public in 2016. However, ClickHouse rapidly found broad swathes of supporters due to its flexibility and easily configurable infrastructure.
This DBMS has an open-source version for on-premises deployments and an upcoming cloud version (currently in early access). The tool also comes with a customizable self-service interface, fewer constraints in database scaling patterns and performance optimization strategies.
Manageability
Unlike Redshift and BigQuery, ClickHouse assumes a more hands-on approach to database management. You can select any cloud storage provider and design a custom data storage architecture according to your needs.
However, if ever you need to increase the number of clusters or add more data replicas, you’d have to manually migrate data and implement proper configurations. That said, you won’t have any overhead for automatic platform management.
Yet, you’ll have to pay separately for ETL tools for data discovery and job scheduling. Though you can always go for an open-source version to trim the costs. On the pro side, ClickHouse has native integrations for data ingestion with Amazon S3 and Kafka, which makes querying easier.
ClickHouse supports multi-region replication (i.e., hosting clusters in different regions), but there are some constraints. To maintain low latency, ClickHouse recommends avoiding data replication across regions (e.g., US and EU). With CSP offerings, low-latency, cross-border data replication is easier to achieve.
DevOps expertise
To operate ClickHouse, you need strong DevOps expertise. To deploy a cluster on ClickHouse, you often have to use Apache ZooKeeper — an auxiliary service, enabling distributed synchronization of nodes. Without proper synchronization controls, you’ll risk running into duplicate replication (i.e., having duplicate data in data replicas). This takes extra effort to be resolved and — obviously, should be avoided.
A DevOps specialist familiar with ClickHouse helps avoid common database deployment and management mistakes. Moreover, they can design a reference system for standard deployments (based on the data volumes you process), then automate proper resource provisioning and data replication across regions. Effectively, they cover the tasks CSP products have automated but tailor the systems’ performance to your business needs.
Performance optimization
By design, ClickHouse already has a very fast data insert rate performance. This means you can provide more timely reporting to your clients and resurface unique business insights faster.
Also, ClickHouse lets you control the number of machines in operation — and up/down-scale your capacities as you see fit (rather than relying on generalized, algorithmic insights). Again, an experienced DevOps can orchestrate a more (cost-) efficient analytics processing setup than a CSP algorithm could suggest.
Next, you can optimize ClickHouse databases using indexes — the essential strategy for improving database querying speed. BigQuerry and RedShift don’t let you do much in this department.
Compared to RedShift and BigQuery, ClickHouse also has better options for data compression:
- LZ4 is the fastest option, but with a smaller compression ratio, compared to others.
- ZSTD is slower than LZ4 but faster and better than a traditional Zlib.
Additionally, ClickHouse has tools for doing lower-level database optimizations, such as implementing SSD cache, which also provides an advantage in performance.
Cloud agnostic
You can run an open-source ClickHouse version on any cloud platform and even on a server on-premises. This gives you more room for crafting the optimal data storage architecture and prevents lock-in with a single provider.
ClickHouse also just launched a managed AWS deployment offer, but it’s still in early access.
Costs
ClickHouse DBMS is free. You don’t pay anything for the software, only for your data storage and some extra for data processing.
CSP-managed services have an attractive “starter” price tag. Yet, managed services will cost a lot if you are dealing with big data volumes.
Choosing an optimal DBMS for your AdTech project
When selecting the optimal database, take four criteria into account:
- Data management expertise
- Load-tolerance requirements
- Available funding
- Performance needs
Data load volumes directly impact the latter ones. As your data volumes increase, you’d have to optimize your database performance to maintain the same product performance. For that, you’d likely require extra DevOps expertise and a bigger budget (if you stay with a managed services provider).
Our best advice? Test different database architectures to select the optimal solution. Upload different data volumes, adjust indexes, tweak data compression, and monitor how the system performance changes. Once you understand what tiny factors affect your database performance, you can apply hotfixes.
ClickHouse is better suited for AdTech projects because it supports more dimensions for data analysis and offers better database performance optimization controls.
- ClickHouse has multiple indexes (Primary indexes, Skipping indexes, MergeTree Indexes, Join indexes). Redshift has none. BigQuerry lacks secondary indexes.
- Redshift has no table partitions. Instead, you have to rely on user-defined distribution and sort keys to optimize for speed. ClickHouse supports Partitioning and Merge Tree Indexes — approaches that lead to better speeds.
- ClickHouse also has support for semi-structured data and JSON functions within SQL, including Lambda expressions. BigQuerry and Redshift support neither of these.
Big Query and Redshift are perfect for a “hands-off approach” — you set the operations on autopilot and hope for the best outcomes. However, these solutions can be a significant strain on your budget.
In contrast, to operate ClickHouse, you need to have DevOps and database experts. However, with the right design, ClickHouse can yield faster data processing speeds, better database performance, and substantial cost savings compared to managed providers.
Contact Xenoss to receive personalized consultation on the optimal ways for enhancing your platform’s database performance and TCO.


