Managing data in digital advertising is another dimension of difficulty compared to other industries. AdTech companies have to maintain ultra-low latency and uber-high data processing speeds to accommodate zettabytes of real-time data coming hot from all the ecosystem partners.
The consequences of delayed or incomplete data are high for AdTech–poor attribution, eschewed reporting, lost auctions, frustrated customers, and reduced revenue.
Every data engineer will tell you that building data pipelines is a tough, time-consuming, and costly process, especially in the AdTech industry, where we’re dealing with massive volumes of asynchronous, event-driven data.
In this post, we’ll talk about:
- The complexities of big data in AdTech
- Emerging trends and new approaches to data pipeline architecture.
- System design and development best practices from industry leaders
Why data in AdTech is complex
The volume, variety, and velocity of data in AdTech are humongous. TripleLift’s programmatic ad platform, for example, processes over 4 billion ad requests and over 140 billion bid requests per day, which translates to 13 million unique aggregate rows in its databases per hour and over 36 GB of new data added to its Apache Druid storage.
The second key characteristic of data in AdTech is its wide variety. The industry processes petabytes of structured and unstructured data generated from user behavior, ad engagement, programmatic ad auctions, and private data exchanges, among other elements in the chain.
In each case, the incoming data can have multiple dimensions. For one ad impression, you need to track multiple parameters like “time window,” “geolocation,” “user ID,” etc. Combined, these parameters create specific measures—analytics on specific events such as click-through rate (CTR), conversion, viewability, revenue, etc.
These events are often distributed in time and happen a million times per day. In other words, your big data pipeline architecture needs to be designed to process asynchronous data at scale.
Large data volumes also translate to high data storage costs. As the big data volumes continue to increase, permanent retention of all information will be plainly unfeasible. So AdTech companies are also facing the tough choice of optimizing their data storage infrastructure to balance data retention vs. operating costs.
Trends in data pipeline architecture for AdTech
ETL/ELT pipelines have been around since the early days of data analytics. Although many of the best practices in conceptual design are still applicable today, major advances in database design and cloud computing have changed the game.
Over 66% of companies used cloud-based data pipelines and data storage solutions, with a third using a combination of both. Cloud-native ETL tools have greater scalability potential and support a broader selection of data sources. Serverless solutions also remove the burden of infrastructure management.
Real-time data processing also progressively replaces standard batch ingestion. Distributed stream-processing platforms like Apache Kafka and Amazon Kinesis enable continuous data collection from a firehose of data sources in a standard message format. Data gets then uploaded to cloud object stores (data lakes) and made available for querying engines.
PubMatic, for example, uses Kinetica to enable blazing-fast data ingestion, storage, and processing for its real-time reporting and ad-pacing engine. Thanks to data streaming architecture, Pubmatic can process over a trillion ad impressions monthly with high speed and accuracy.
That said, because most of the information is an event, AdTech companies often rely on a combination of real-time and batch data processing. For example, streaming data on ad viewability can be used and then enriched with some batch data on past inventory performance.
As the data infrastructure expands, AdTech teams also concentrate more efforts on data observability and infrastructure monitoring to eliminate costly downtime and expensive pipeline repairs.
To dive deeper into the current trends in AdTech, we’ve invited Charles Proctor, MarTech Architect at CPMartec and EnquiryLab, to share his insights on real-time processing, AI advancements, cloud solutions, and essential data governance practices. Here’s what he had to say:
Charles Proctor, MarTech Architect at CPMartec and EnquiryLab, on upcoming data pipeline advancements and their impact on AdTech
AdTech data pipeline development: Best practices and recommended technologies
A data pipeline is a sequence of steps: Ingestion, processing, storage, and access. Each of these steps can (and should) be well-architected and optimized for the highest performance levels.
Xenoss big data engineers placed a microscope over the types of data pipeline architectures in AdTech. We evaluated the strengths and weaknesses of different architecture design patterns and toolkits industry leaders use for AdTech analytics and reporting.
Our analysis extended to both logical and platform levels, providing a comprehensive understanding of the data processing ecosystem. The logical design describes how data is processed and transformed from the source into the target, ensuring consistent data transformation across different environments. In contrast, the platform design focuses on the specific implementation and tooling required by each environment, whether it’s GCP, Azure, or Amazon. While each platform offers a unique set of tools for data transformation, the goal of the logical design remains the same: efficient and effective data transformation regardless of the provider.
Data ingestion
AdTech data originates from multiple sources — DSP and SSP partners, customer data platforms (CDP), or even DOOH devices. To extract data from a source designation, you need to make API calls, query the database, or process log files.
The challenge, however, is that in AdTech, you need to simultaneously ingest multiple streams in the pipeline — and that’s no small task (pun intended).
TripleLift, for example, needed its data pipelines to handle:
- Up to 30 billion event logs per day
- Normalized aggregation of 75 dimensions and 55 metrics
- Over 15 hourly jobs for ingesting and aggregating data into BI tools
And all of the above have to be in a cost-effective manner, with data delivery happening within expected customer SLAs.
The TrifpleLift’s team organized all incoming event data streams into 50+ Kafka topics. Events are consumed by Secor (a Pinterest open-source consumer) and written to AWS S3 in parquet format. TripleLift uses Apache Airflow to schedule batch jobs and manage dependencies for data aggregation into its data stores and subsequent data exposure to different reporting tools.

Aggregation tasks are done with Apache Spark on Databricks clusters. The data is denormalized into wide tables by joining raw event logs in order to paint a complete picture of what happened pre-, during, and after an auction. Denormalized logs are stored in Amazon S3.
In such a setup, Kafka helps make the required data streams available to different consumers simultaneously. Thanks to horizontal scaling, you can also maintain high throughput even for extra-large data volumes. You can also configure different retention policies for different Kafka topics to optimize cloud infrastructure costs.
Thanks to in-memory data processing, Apache Spark can perform data aggregation tasks at blazing speeds. It’s also a highly versatile tool, supporting multiple file formats, such as Parquet, Avro, JSON, and CSV, which makes it great for handling different data sources.
Pubmatic also relies on Apache Spark as the main technology for its data ingestion model. The team opted to use Spark Structured Streaming—a fault-tolerant stream processing engine built on the Spark SQL engine —and FlatMap to transform their datasets. In Pubmatic’s case, FlatMap delivered a 25% better performance than MapPartitions (another popular solution for distributed data transformations). With a new data ingestion module, Pubmatic can process 1.5X to 2X more data with the same number of resources.
Recommended technologies for data ingestion:
- Apache Kafka: An open-source distributed event streaming platform. Kafka’s high throughput and fault tolerance make it suitable for capturing and processing large volumes of ad impressions and user interactions in real-time, enabling immediate processing and analysis.
- Amazon Kinesis: A managed framework for real-time video and data streams.A strong choice for AWS users, providing managed, scalable real-time processing with seamless integration into the AWS ecosystem. Kinesis facilitates low-latency data processing and high availability, making it effective for real-time analytics in AdTech environments.
- Apache Flume: An open-source data ingestion tool for collection, aggregation, and transportation of log data. Specialized for log data, Flume can be effective in environments requiring robust log data collection and integration with Hadoop for further analysis.
Data processing
Ingested AdTech data must then be brought into an analytics-ready state. Depending on your setup, you may codify automatic:
- Schema application
- Deduplication
- Aggregation
- Filtering
- Enriching
- Splitting
The problem? Data transformation can be complex and expensive if you use outdated ETL technology.
Take it from AppsFlyer, whose attribution SDK is installed on 95% of mobile devices worldwide. The company collected ample data, but operationalizing it was an uphill battle.
Originally, AppsFlyer built an in-house ETL tool to channel event data from Kafka to a BigQuerry warehouse. Yet, as Avner Livne, AppsFlyer Real-Time Application (RTA) Groups Lead, explained: “Data transformation was very hard. Schema changes were very hard. While [the system] was functional, everything required a lot of attention and engineering”. In fact, one analytics use case costs AppsFlyer over $3,000 per day on BigQuery and over $1.1 million annually.
The team used the Upsolver cloud-native data pipeline development platform to improve its data ingestion and transformation capabilities. After all the necessary transformations on S3 data have been performed, Upsolver’s visual IDE and SQL help make the data query ready via the AWS Glue Data Catalog.
Upsolver’s engine proved to be more cost-effective than the in-house ELT tool. AppsFlyer also substantially improved its visibility into stream log records, which allowed the company to reduce the size of created tables, leading to further cost savings.
At Xenoss, we also frequently saw cases when clients’ infrastructure costs spiral out of control—and we specialize in getting them back on track. Among other projects, our team has helped programmatic ad marketplace PowerLinks reduce its monthly infrastructure costs from $200k+ per month to $8k-10k without any performance losses. On the contrary, the volume of inbound traffic went from 20 to 80 QPS during our partnership, and we’ve implemented scaling possibility to up to 1 million QPS.
Recommended technologies for data processing:
- Google Cloud Dataflow: A managed streaming analytics service.
- Apache Flink: A unified stream-processing and batch-processing framework.
- Apache Spark: A multi-language, scalable data querying engine.
Data storage
All the collected and processed AdTech data needs a “landing pad”—a target storage destination from where it will be queried by different analytics apps and custom scripts.
In most cases, data ends up in either of the following locations:
- Data lake (e.g., based on AWS S3, Hadoop HDFS, Databricks)
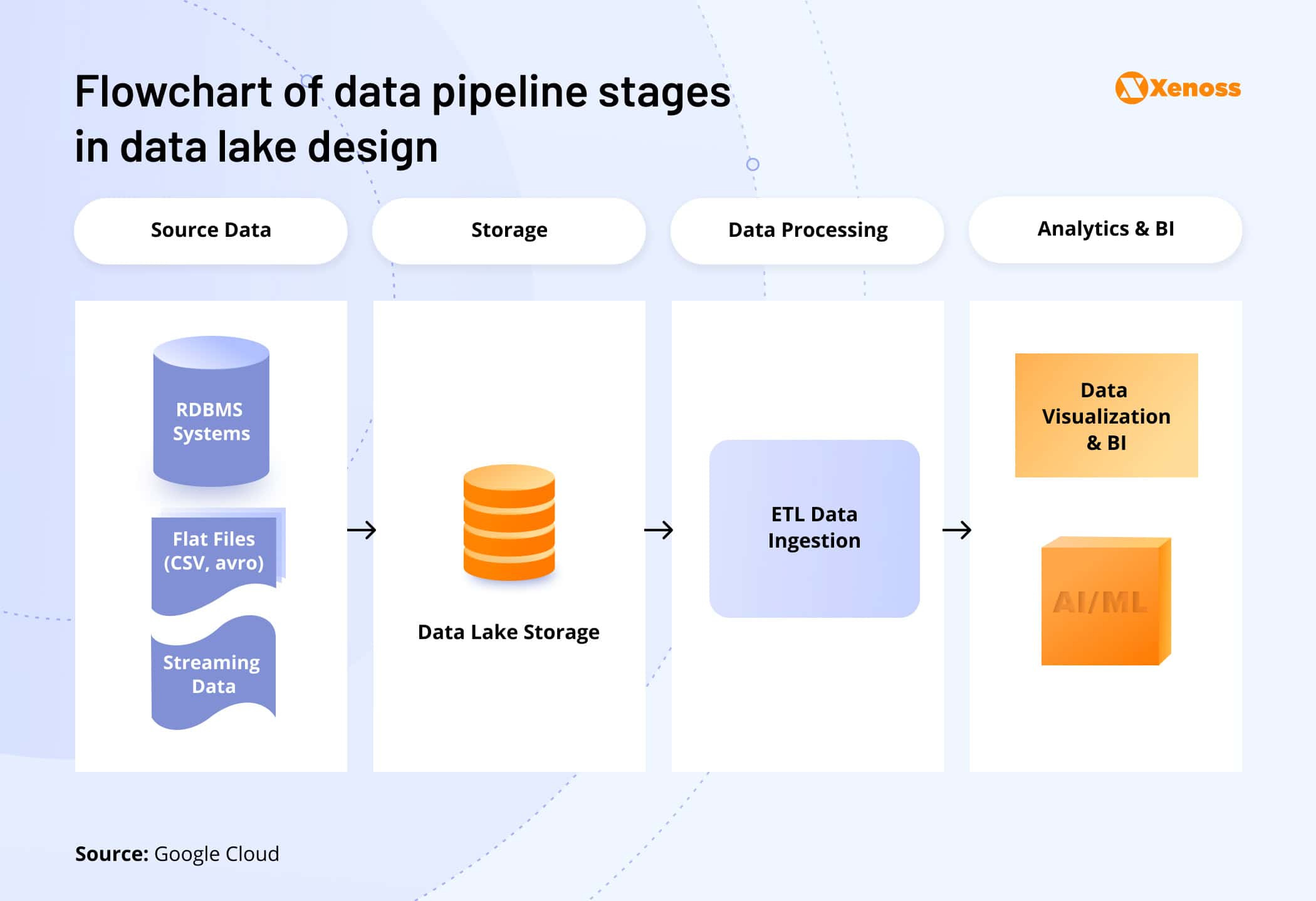
- Data warehouses (e.g., Amazon Redshift, BigQuery, Apache Hive, Snowflake)
But that’s not the end of the story. You also need suitable analytic database management software to ensure that data gets stored in the right format and can be effectively queried by downstream applications.
That’s where database management systems (DBMS) come into play. A well-selected DBMS can automate data provisioning to multiple apps and ensure better data governance and cost-effective operating costs.
DoubleVerify, for example, originally relied on a monolithic Python application for AdTech data analysis. Data was hosted in several storage locations, but the most frequent one was the columnar database Vertica, where request logs went.
The team created custom Python functions to orchestrate SQL scripts against Vertica. For fault tolerance, Python code was deployed to two on-premises servers—one primary and one secondary. Using the job scheduling software Rundeck, the code was executed using a cron schedule.
As data volumes increased, the team soon ran into issues with Vertica. According to Dennis Levin, Senior Software Engineer at DoubleVerify, jobs on Vertica were taking too long to run while adding more nodes to Vertica was both time-consuming and expensive. Due to upstream dependencies, the team also had to run most jobs on ancient Python v2.7.
To patch things up, the team came up with a new cloud-native data people architecture built with DBT, Airflow, and Snowflake.
DBT is a SQL-first transformation workflow that allows teams to deploy analytics code faster by adding best practices like modularity, portability, and CI/CD. In DoubleVerify’s case, DBT replaced ancient Python code.
The team also replaced Vertica with a cloud-native Snowflake SQL database. Unlike legacy data warehousing solutions, Snowflake can natively store and process both structured (i.e., relational) and semi-structured (e.g., JSON, Avro, XML) — all in a single system, which is convenient for deploying multiple AdTech analytics use cases.
DoubleVerify also replaced Rundeck with Apache Airflow — a modern, scalable workflow management platform. It was configured to run in Google’s data workflow orchestration service, Cloud Composer (which is built on Apache Airflow open source project).
Cloud Composer helps author, schedule, and monitor pipelines across hybrid and multi-cloud environments. Since pipelines are configured as directed acyclic graphs (DAGs), the adoption curve is low for any Python developer.
To avoid the scalability constraints of SQL databases, some AdTech companies go with non-relational databases instead. NoSQL databases have greater schema flexibility and higher scalability potential. Modern non-relational databases also use in-memory storage and distributed architectures to deliver lower latency and faster processing speeds.
The flip side, however, is that greater scalability often translates to higher operating costs. A poorly configured cloud NoSQL database can easily generate a $72,000 overnight bill. One possible solution is using a mix of hot and cold storage for different types of data streams as The Trade Desk does.
TTD receives over 100K QPS of data from its partners, which translates to over 200 TDID/segment updates per second. Given the volumes and costs of merging records, TTD needs to pick the “best” elements for analysis if any given record is too large. At the same time, the platform needs to only serve data on the record in use by an active campaign.
To manage this scale, the team uses Aerospike—a multi-model, multi-cloud NoSQL database. Aerospike runs on the edge as a hot cache destination for the real-time bidding system, which processes over 800 billion queries per day. It also serves as a System of record on AWS for managing peak loads of up to 20 million writes per second for its “cold storage” of user profiles.
This way, TTD can:
- Rapidly serve data required for active campaigns
- Refresh hot records within hours of new campaign activation
- Forget about any impact of data delivery on bidding system performance
- Support advanced analytics scenarios by surfacing cold storage cluster data.
Such a data pipeline architecture allows TTD to maintain large-scale multidimensional data records dimensions without burning unnecessary CPU costs and thaw data in 8ms for real-time bidding.
Recommended technologies for data storage:
- Clickhouse: A cost-effective RDBMS for large-scale AdTech projects.
- Aerospike: A schemaless distributed database with a distinct data model for organizing and storing its data, designed for scalability and high performance.
- Apache Hive: A distributed, fault-tolerant data warehouse system.
Data access
The final step is building an easy data querying experience for users and enabling effective data access to downstream analytics applications.
Query engines help retrieve, filter, aggregate, and analyze the available AdTech data. Modern query engine services support multiple data sources and file formats, making them highly scalable and elastic for processing data within the data lake instead of pushing it into a data warehouse.
That’s the route Captify — a search intelligence platform — chose for its data pipelines for reporting. According to Roksolana Diachuk, the platform’s Engineering Manager, the team uses:
- Amazon S3 to store customer data in various formats (CSV, parquet, etc.)
- Apache Spark for processing the stored data.
To ensure effective processing, the team built a custom on top of Amazon S3 client called S3 Lister, which filters our historical records so the team doesn’t need to query with Spark. Since the data arrives in different formats, Captify applies data partitioning at the end of its data pipeline. Data partitioning is based on timestamps (date, time, and hour) as it is required for their reporting use case. Afterwards, all processed data is loaded to Impala, a query engine built on top of Apache HDFS.
Similar to The Trade Desk, Captify uses a system of hot and cold data caches. Typically, all data streams are saved for 30 months for reporting purposes. However, teams only need data from the past month or so for most reporting use cases.
Therefore, HDFS contains fresh data, which is several months old at max. All historical data records, in turn, rest in S3 stores. This way, Captify can maintain high-speed and cost-effective data querying speeds.
That said, SQL querying requires technical expertise, meaning that average business users have to rely on data science teams for report generation. For that reason, AdTech players also leverage self-service BI tools.
Tokyo-based CyberAgent, for example, went with Tableau—a self-service analytics platform. TTableau has pre-made connectors to data sources like Amazon Redshift and Google BigQuery among others, and helps build analytical models visually to provide business users with streamlined access to analytics.
CyberAgent stores petabytes of data across Hadoop, Redshift, and BigQuerry. Occasionally, they also use data marts to import data from MySQL and CSV files. According to Ken Takao, Infrastructure Manager at CyberAgent, the company “uses MySQL to store the master data for most of the products. Then blend the master data on MySQL and data on Hadoop or Redshift to extract”.
Before Tableau, the company’s engineers spent a lot of time figuring out how to obtain the required data before scripting custom SQL queries. Tableau now allows them to extract data directly from connected insights and make it available to downstream applications. This saves the engineering teams dozens of hours. Business users benefit from readily accessible insights on ad distribution, logistics, and sales volumes for the company’s portfolio of 20 products.
Both Tableau and Looker are popular data visualization solutions, but they have some limitations for AdTech data. In particular, some analytics use cases may require heavy, mostly manual data porting.
Ideally, you should build or look for a solution that supports automatic data collection from multiple systems. Media-specific data visualization solutions often have field normalization, which eliminates the need for manual data mapping and improves the granularity of data presentation.
Recommended technologies to provide effective data access:
- Amazon Athena: A serverless, interactive analytics service built on open-source frameworks.
- Presto: An open-source SQL query engine that allows querying Hadoop, Cassandra, Kafka, AWS S3, Alluxio, MySQL, MongoDB, and Teradata.
- Apache Impala: An open source, distributed SQL query engine for Apache Hadoop.
- Tableau: A flexible self-service business intelligence platform.
Data orchestration
Poor data pipeline management affects almost everything—data quality, processing speed, data governance. The biggest challenge, however, is that AdTech data pipelines have complex, multi-step workflows—and “clogging” at any step can affect the entire system’s performance.
Moreover, workflows have upstream, downstream, and interdependencies. Without a robust data orchestration system, managing all of these effectively is nearly impossible.
The simplest (and still most-used) orchestration method used for ETL pipelines is sequential scheduling via cron jobs. While it’s still a workable option for simple analytics use cases, it doesn’t scale well, plus requires significant developer time for configuration, upkeep, and error handling.
Orchestration is also challenging in data pipelines for streaming data processing. A batch orchestrator relies on idempotent steps in a pipeline, whereas real-life processes are seldom idempotent. Therefore, when you need to roll back or replay a workflow, data quality and integrity issues may arise.
In AdTech, data engineers also often need to enrich events in a stream with batch data to obtain more comprehensive insights. For example, when you need to contextualize an ad click event using user interaction data, stored in a database. This requires pipeline synchronization.
Modern orchestration tools like Airflow and AWS Step Functions, among others help deal with the above challenges through the concept of Direct Acyclic Graphs (DAG). DAGs help record the underlying task nodes in a graph and task dependencies—as edges between these nodes. Thanks to this, the system can execute concurrent tasks in a more efficient way, while data engineers get better controls for logging, debugging, and job re-runs.
For example, with an Airflow-based orchestration service, Adobe can now run over 1000+ concurrent workflows for its Experience Management platform. Arpeely, in turn, went with Google Cloud Composer and Cloud Scheduler to automate data workflows for its autonomous media engine solution.
Overall, orchestration services provide a convenient toolkit to streamline and automate complex data processing tasks, allowing your teams to focus on system fine-tuning instead of endless debugging.
Recommended technologies for data orchestration:
- Apache Airflow: An open-source workflow management platform for data engineering pipelines, originally developed by Airbnb.
- AWS Step Functions: A serverless workflow orchestration service offering seamless integration with AWS Lambda, AWS Batch, AWS Fargate, Amazon ECS, Amazon SQS, Amazon SNS, and AWS Glue.
- Luigi: An open-source orchestration solution from the Spotify team.
- Dagster: A cloud-native orchestrator improving upon Airflow.
Monitoring
Similar to regular pipes, big data pipelines also need servicing. Job scheduling conflicts, data format changes, configuration problems, errors in data transformation logic—a lot of things can cause havoc in your systems. And downtime is costly in AdTech.
High system reliability requires end-to-end observability of the data pipeline, coupled with the ability to effectively prevent and optimize the flow of data to avoid bottlenecks, increase resource efficiency, and optimize operation costs.
In particular, AdTech companies should implement:
- Compute performance monitoring
- Data reconciliation processes
- Schema and data drift monitoring
Soundly, these tasks can be automated with data observability platforms. PubMatic, for example, uses Acceldata Pulse to monitor the performance of its massive data platform, spanning over thousands of nodes handling hundreds of petabytes of data.
The sheer scale of operations caused frequent performance issues, while Mean Time to Resolve (MTTR) stayed high. Acceldata’s observability platform helped PubMatic’s data engineers locate and isolate data bottlenecks faster, plus automate a lot of infrastructure support tasks. Thanks to the obtained insights, PubMatic also reduced its HDFS block footprint by 30% and consolidated its Kafka clusters, resulting in lower costs.
At Xenoss, we also built a custom pipeline monitoring stack using Prometheus and Grafana, which allows us to keep a 24/7 watch over all data processing operations and rapidly respond to errors and failures. This is one of the most well-balanced and efficient stacks we’ve compiled and have successfully implemented across various client businesses.
Recommended technologies for data pipeline monitoring:
- Grafana: An open-source, multi-platform service for analytics and interactive visualizations.
- Datadog: A SaaS monitoring and security platform.
- Splunk: A leader in application management, security, and compliance analytics.
- Dynatrace: An observability, AI, automation, and application security functionality meshed in one platform.
Final thoughts
Data pipelines are the lifeline of the AdTech industry. But building them is hard. There are always trade-offs between cost vs. performance.
Development of robust, scalable, and high-concurrency data pipelines requires a deep understanding of the AdTech industry and prolific knowledge of different technologies and system design strategies. Partnering with a team of AdTech data engineers is your best way to avoid subpar architecture choices and costly operating mistakes.
Xenoss’ big data engineers have helped architected some of the most robust products in the industry, a gaming advertising platform with 1.4 billion monthly video impressions, and a performance-oriented mobile DSP, recently acquired by the Verve Group.
We know how to build high-load products for high-ambition teams. Contact us to learn more about our custom software development services.


