Reflecting on the state of AI in 2025 feels unusual because of the hyper-optimistic view we entered the year with (think about Dario Amodei’s prediction that 90% of code will be AI-generated) and the sober reckoning the AI community experienced in the latter half of 2025.
Technically, LLM capabilities improved across the board. We got smarter coding models, improved data processing, longer focus times, better image generation, and excellent video generation.
AI agents, although not new, have found their place in the enterprise, and more companies now have a vision for specific use cases where AI agents can provide support.
At the same time, halfway through the year, it became clear that “AGI by 2027” predictions are too far-fetched. Despite improvements, models continued to hallucinate and make embarrassing mistakes, making it harder to imagine AI reliably running any complex process end-to-end.
As the AI community had to accept the reckoning, fear started creeping in on whether the global economy is not putting too much stock in the AI bubble and what the world will look like if that bubble collapses.
This review covers what mattered most in 2025: releases, wins, and risks of AI adoption in the enterprise, the state of the talent market, and the global impact of the AI explosion.
1. Anthropic and Google caught up to OpenAI
At the start of the year, OpenAI’s GPT o3 was one of the most powerful chain-of-thought models.
But by the end of the year, OpenAI no longer holds a decisive technical lead. Google and Anthropic caught up to the AI race with powerful models.
At the time of writing, Gemini 3, GPT-5.2, and Claude 4.5. seem to be locked in a stalemate when it comes to agentic task completion, coding, multi-modal generation, and document processing.
On the other hand, Amazon, Meta, and Apple have fallen behind and not made meaningful LLM contributions this year.
The table below recaps the top large language models released by three leading AI labs in 2025 and the impact of each on the development of machine learning.
| Jan 31 | o3-mini (OpenAI) | Cheaper “reasoning-tier” model | Put reasoning into high-volume, cost-sensitive production workloads |
| Late Jan | R1 (DeepSeek) | Cost-disruptive reasoning baseline | Forced a price/performance reset and intensified “efficiency race” narratives |
| Feb 19 | Grok 3 (xAI) | Frontier entrant + “search/deep research” style workflows | Increased competitive cadence; broadened distribution-driven adoption pressure |
| Feb 24 | Claude 3.7 Sonnet (Anthropic) | Hybrid “fast vs extended thinking” control | Normalized reasoning as a user-controlled dial for coding/analysis workflows |
| Feb 27 | GPT-4.5 (OpenAI) | Compute-heavy flagship iteration | Reinforced frontier pace while highlighting the cost of pure scaling |
| Feb 27 | Hunyuan Turbo S (Tencent) | Latency-first optimization | Strengthened the bifurcation: ultra-fast assistants vs deep reasoning models |
| Mar 16 | ERNIE 4.5 + ERNIE X1 (Baidu) | Multimodal and “deep thinking” lineup | Increased China-side competitive intensity; pushed price/perf competition |
| Mar 25 | Gemini 2.5 Pro (Experimental) (Google) | “Thinking model” positioning | Re-anchored expectations: top-tier models must ship with deliberation modes |
| Apr 05 | Llama 4 (Scout, Maverick) (Meta, open-weight) | Multimodal and MoE at scale | Expanded supply and down-market availability; pressured closed-model pricing |
| Apr 14 | GPT-4.1 (mini, nano) (OpenAI) | Developer-oriented family and smaller tier | Made “model families” (cost/latency tiers) the default procurement pattern |
| Apr 16 | o3 + o4-mini (OpenAI) | Production-grade reasoning and tool use | Raised the baseline for agents: multi-step execution over chat quality alone |
| May 22 | Claude 4 (Opus 4, Sonnet 4) (Anthropic) | Next-gen coding/agent focus | Escalated “agentic coding” competition and sped up enterprise adoption |
| Jun 17 | Gemini 2.5 Pro (GA on Vertex AI) (Google) | Enterprise hardening and cloud distribution | Reduced deployment friction in regulated orgs; accelerated “procure-and-deploy.” |
| Aug 07 | GPT-5 (OpenAI) | Default “adaptive reasoning/router” | Made adaptive reasoning a mainstream expectation (and raised buyer scrutiny) |
| Nov 12 | GPT-5.1 (OpenAI) | Post-flagship iteration | Compressed release cycles; normalized continuous model upgrades as a market norm |
| Nov 18 | Gemini 3 Pro (Google) | Flagship jump and agentic narrative | Rebalanced late-year leadership perceptions; leveraged Google distribution |
| Nov 24 | Claude Opus 4.5 (Anthropic) | High-end “deep work” coding/agents | Tightened the “best model for coding/agents” race; encouraged multi-model stacks |
| Dec 02 | Nova 2 (AWS) | Bedrock-native general models | Strengthened hyperscaler-first buying: models inside existing cloud controls |
| Dec 11 | GPT-5.2 (OpenAI) | Further GPT-5-line iteration | Reinforced frontier models as continuously deployed product lines |
| Dec 17 | Gemini 3 Flash (Google) | Fast/cheap tier with strong baseline | Expanded addressable use cases via latency and cost, intensifying price pressure |
It’s fascinating to think about how much the approach AI labs take to building frontier models has changed since the first LLM release of 2025 (o3-mini).
With Claude 3.7 as the trendsetter, LLMs started giving users more control over how long a model should think on a query. Now, AI labs allow users to enable or disable “Extended thinking” that encourages LLMs to think “deeper” about the prompt.
Another area where AI labs have leaped astronomically is context windows. Gemini 3 Pro and Claude 4.5 Sonnet have a context window of 1 million tokens, GPT-5.2 supports up to 400,000 prompt tokens.
Now that there are fewer concerns over LLMs’ capability to digest high data volumes, enterprise teams can train off-the-shelf models on higher volumes of corporate data without necessarily requiring a separate RAG module.
Another important shift is how significantly the focus on LLM performance has shifted towards engineers. OpenAI’s release of 4.1. was API-only and marketed as an “improved coding model”.
When launching o3 and o4, Sam Altman’s team also focused on math, science, and coding benchmarks to prove the excellence of these models.
In the same vein, Anthropic didn’t implement image and video generation – instead, the company positioned Claude 4 as the “world’s best coding model”, capable of not losing focus on long-running tasks and multi-step agentic workflows.
Google also emphasized improved agentic coding skills in Gemini 3 Pro documentation and increased the context window size to let teams feed entire code repositories to the model.
This positioning tracks with where enterprises see the fastest, most defensible ROI: software delivery, workflow automation, and operational copilots. But it also creates a perception risk. When labs optimize their narratives around engineering benchmarks, non-technical users can read it as a deprioritization of writing quality, creativity, and broader “everyday” usefulness.
The takeaway: By the end of 2025, frontier LLM development looked less like a single-lab advantage and more like convergence across three major players.
Differentiation shifted toward product strategy and distribution, including reasoning modes, cost and latency tiers, context scale, and enterprise deployment controls.
2. Open-source LLMs went mainstream
Before this year, there were only a handful of open models capable of rivaling GPT, Claude, and Gemini in evaluations, with Mistral and Llama model families leading the landscape.
However, after DeepSeek R1 was released on January 20th, 2025, and took over the LLM community, open-source models became so influential that even SOTA AI labs had to admit to being on “the wrong side of history”.
Following high demand from engineers, AWS, Google Cloud, and Microsoft Azure added the model to their offerings, allowing teams to comfortably add it to their AI products.
Throughout the year, the open-source boom continued, mostly led by Chinese AI labs. Out of US-based models, GPT-oss was the most powerful open-source model released in 2025, though the AI community argued it tied Kimi K2 on most benchmarks.
| Jan 20 | DeepSeek-R1 (DeepSeek) | Reasoning LLM (open-weights) | R1 (family release) | Open-weights (public) | Major “open reasoning” moment that intensified price/perf pressure on closed frontier labs. |
| Apr 5 | Llama 4 Scout / Maverick (Meta) | Natively multimodal, open-weight | Scout, Maverick (Meta “herd”) | Open-weight (Meta license) | Put strong multimodal open weights into builders’ hands and raised the baseline for what “open” can do. |
| Apr 28–29 | Qwen3 family (Alibaba) | Open-source LLM family | Dense: 0.6B–32B; MoE: 30B/235B (A22B) (as listed by project) | Apache 2.0 (open-source) | Scaled open models across many sizes and reinforced open-source as a serious default for production deployments. |
| Mar 24 | Qwen2.5-VL-32B-Instruct (Alibaba) | Vision-language (open-source) | 32B | Apache 2.0 | Strengthened open multimodal options for doc/vision workflows without relying on closed APIs. |
| Mar 26 | Qwen2.5-Omni-7B (Alibaba) | Multimodal and voice (open-source) | 7B | Apache 2.0 | Brought “GPT-4o-style” multimodal I/O (incl. audio) into the open-source ecosystem |
| Jul 23 | Qwen3-Coder (Alibaba) | Coding model (open-source) | (Reported as Alibaba’s most advanced open-source coding model) | Open-source release (weights public) | Escalated the open-source coding arms race and increased competitive pressure on closed coding assistants. |
| Jun 2025 | Mistral Small 3.2 (Mistral) | General LLM (open-weight) | Small 3.2 | Open-weight | A practical “deploy everywhere” open model tier for enterprise cost/latency constraints. |
| Dec 2 | Mistral Large 3 / Mistral 3 (frontier open-weight family) (Mistral) | Frontier open-weight | Large 3; additional open models (as listed) | Open-weight (per Mistral) | Strengthened Europe’s position in open-weight frontier models and widened enterprise alternatives to US closed vendors. |
| Dec 15 | Nemotron 3 (Nano released first) (NVIDIA) | Open-source model family | Nano (released), larger variants announced | Open-source (as reported) | Added a credible US-based open-source option positioned for efficiency and multi-step tasks, amid demand for “non-China” open models in government/regulated settings |
Besides adding variety to the roster of AI models, the open-source explosion shook the standard foundations of generative AI.
Discovery #1: Frontier-level training no longer requires frontier budgets
DeepSeek directly challenged the belief that state-of-the-art performance demands massive teams, proprietary pipelines, and multi-billion-dollar compute clusters. The team reported training costs of approximately $294,000, a negligible figure compared to the estimated $250 billion collectively invested by US-based labs in AI infrastructure in 2025.
Discovery #2: Keeping the codebase private doesn’t help protect AI safety
Before 2025, many AI leaders cautioned against open-sourcing large-language models, arguing that doing so would increase the risk of misuse.
Open models largely undermined that position. Once high-performing weights, fine-tunes, and tooling are widely available, the marginal safety benefit of a single lab keeping its models closed diminishes sharply. Capable systems can be reproduced, adapted, and deployed well outside any one organization’s control.
Closed models can still reduce risk through stronger platform controls and faster patching compared to open-source models, but “closed by default” is no longer a credible standalone safety argument in a world where open alternatives like DeepSeek and Kimi K2 already meet many real-world use cases.
The takeaway: In 2025, open-source LLMs crossed the point of no return: once models like DeepSeek proved that frontier-level performance, low training costs, and cloud-native deployment could coexist, “open” stopped being an alternative and became a default option for builders.
The growth of the open ecosystem put structural pressure on closed labs, and we may be entering the era where capability diffusion, not code secrecy, defines the generative AI landscape.
3. MCP became the number-one agentic connector
In 2024, Anthropic released Model Context Protocol, an open standard that helps connect AI agents to external tools like GitHub, Figma, and others. This year, it went from a niche technology to a universally accepted industry standard.
In March, instead of building a proprietary alternative, OpenAI used MCP to connect its model to external data sources. In April, Google followed suit, and MCP became the universal framework that top models use to connect their agents to other tools.
By the end of the year, MCP adoption surpassed that of tools with a similar purpose (e.g, LangChain).
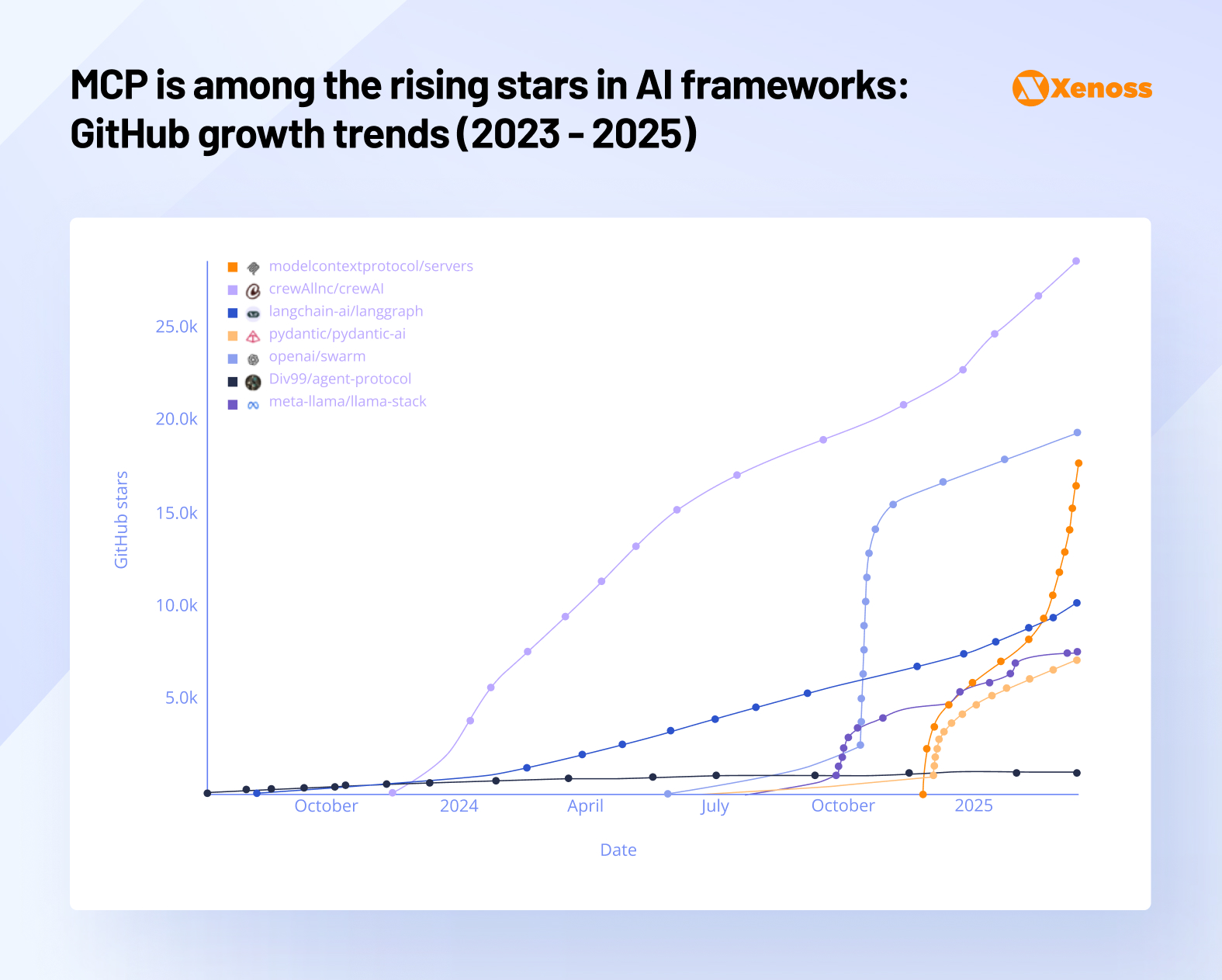
At the time of writing, Anthropic lists over 10,000 active MCP servers. The protocol is actively adopted by engineers, where the Python SDK now has over 97 million downloads.
On the other hand, as MCP adoption grew, teams became more aware of its limitations. Enterprise companies called out Anthropic for weak authorization capabilities, poor integrations with SSO providers, and high risk of prompt injection.

The takeaway: MCP’s rapid adoption demonstrates how open standards can become infrastructure when ecosystem incentives align. However, its spread exposed critical gaps in enterprise readiness: security, identity, and governance weaknesses that must be addressed before production-scale deployment.
4. GPT-5 fueled a wave of speculation on whether LLMs have “peaked”
On August 7, 2025, OpenAI unveiled GPT-5 with a livestream and a ton of fanfare.
Expectations were unusually high. Among researchers, executives, and the broader public, there was a belief that GPT-5 might represent the next meaningful step toward AGI.
It was not.
During the demo livestream, the plots capturing GPT-5’s superior benchmark performance were mislabeled, and the early rollout was riddled with bugs, ranging from simple math to GPT failing to switch to agent mode.

Despite technically sweeping key benchmarks, the real-world impact of GPT-5 felt a lot less significant than that of other releases we got this year, namely Claude 4.
The reason GPT-5 release still deserves a separate spot on our AI recap is that it changes the way we set expectations for AI models – instead of hoping to reach AGI, teams will be hoping to get well-rounded models that don’t feel “dumb” and drive quantifiable productivity gains.
More releases are going to look like Anthropic’s Claude 4, where the benchmark gains are minor, and the real-world gains are a big step. There are plenty of implications for policy, evaluation, and transparency that come with this. It is going to take much more nuance to understand if the pace of progress is continuing, especially as critics of AI are going to seize the opportunity of evaluations flatlining to say that AI is no longer working.
Nathan Lambert, “GPT-5 and the arc of progress”
The fumbled release of GPT also fueled a different debate: are scaling laws hitting a ceiling?
In 2020, when OpenAI published ‘Scaling Laws for Neural Language Models, ’ the idea that throwing exponentially larger datasets at models would make them exceptionally powerful was quite bold.
However, when OpenAI applied it in practice with GPT-3, and then, even more convincingly, with GPT-4, scaling laws became the guiding principle of LLM training.
Despite throwing more data and compute at newer generations of models with GPT-5, as well as other LLMs, they fail to deliver significant intelligence leaps.
The doubt about the limitations of scaling laws, initially raised by a small group of skeptics (led by Gary Marcus, an AI researcher and author), is becoming mainstream.
Engineering teams are exploring alternative methods for model improvements.
Post-training techniques, reinforcement learning refinements, and fine-tuning strategies that help models better interpret existing data became standard practice. These methods improved reliability and task performance, but none yet matched the transformative impact scaling had earlier in the decade.
The takeaway: Despite significant improvements in coding and math LLMs reached in the beginning of the year, the AI community is looking into 2026 with uncertainty about the future of this technology. It will take a new substantial breakthrough to convince an increasingly skeptical crowd that large-language models are really a bridge to AGI.
5. AI agents became the hottest corporate AI application of 2025
This year, AI agents went from the technology accessible primarily to frontier labs (the technology itself went mainstream in January when OpenAI released Operator) to a practical tool that enterprises adopted to streamline workflows.
The first major agentic releases coming outside of leading AI companies were Agentforce 2dx by Salesforce and Joule Studio by SAP.
Unlike OpenAI’s general-purpose agents, these niche releases cover a smaller list of applications. Salesforce’s agent helps sales, marketing, and customer success manage client tickets and sales pipelines, while SAP Joule Studio offers tools for automating workflows in HR, finance, and supply chain.
By mid-year, it became clear that niche, workflow-specific agents delivered more value to enterprises than general-purpose agents. Constraining scope reduced hallucinations, simplified governance, and made ROI easier to measure.
By December 2025, major Fortune 500 companies will have successfully dabbled in building both internal and user-facing AI agents.
To support growing interest in agentic systems, cloud vendors and data platforms are building an infrastructure to support AI agents.
Databricks empowers enterprise teams with a dedicated toolset for agent development that includes Mosaic AI Agent Framework, Unity Catalog, and built-in evaluation and monitoring tools.
With these services, teams can build agents that safely reason over proprietary data, invoke tools, and operate inside governed production environments.
AWS Bedrock helps enterprises bring agents to production with Amazon Bedrock AgentCore. The platform is a one-stop shop for building, deploying, operating, securing, and monitoring agents at scale. With AgentCore, engineers who host their infrastructure on AWS can connect multi-agent workflows to AWS-native identity, permissions, and data stack.
The takeaway: Agentic systems are still in their early stages, but a powerful infrastructure to help deploy and scale autonomous workflows is developing rapidly.
Companies began seeing first wins from AI agent adoption in increased employee productivity, reduced error rate on manual tasks, and improved cross-department workflow integration.
The next phase will be less about agent novelty and more about disciplined execution, governance, and scaling agents into core business processes.
6. “Vibe coding” took over no-code and prototyping
When Andrej Karpathy coined the term “vibe coding” in a tweet, he probably anticipated AI-assisted coding to become a trend. Still, it’s unlikely he predicted the speed with which his new term became a buzzword in the AI community.

In early 2025, tools like Cursor and Microsoft Copilot were already empowering hands-off programming, but the inflection point came in late February, when Anthropic released Claude 3.7 and previewed Claude Code.
Claude Code was no longer just auto-complete. It wrote and read code, edited files, wrote tests, pushed code to GitHub, and used the CLI with minimal human involvement.
Claude Code gave engineers a massive productivity boost, allowing them to build up to four projects at a time, but, at the end of the day, it is still an engineer-facing tool.
Vibe-coding went mainstream when tools like Lovable and Replit gave team managers and entrepreneurs with a layman’s understanding of engineering the power to transform plain-language ideas into ready-to-deploy pilots.
In the year since its release, Lovable has hit 8 million users and has been used by over half of Fortune 500 companies.
Among enterprise companies, tools like Lovable or Replit are rarely deployed for user-facing products or internal tools for organization-wide adoption, but are helpful for prototyping.
I used to bring an idea to a meeting. Now I bring a Lovable prototype.
Sebastian Siemiatkowski, CEO of Klarna
Vibe-coding drives real productivity gains.
As with any trend threatening the status quo of traditional engineering departments, vibe-coding is controversial. Users have reported bugs in their Lovable MVPs and, on one occasion, Replit accidentally deleted a user’s entire database.
Nevertheless, vibe coding is likely to stay because it is already delivering tangible value.
A Forrester Research report found that using agentic coding tools saves enterprise companies up to ~$44.5M in risk-adjusted employee time savings over three years. A different survey showed a 206% ROI uplift following vibe coding adoption and a 50% time-to-market reduction.
According to Lovable’s internal data, a prototype built on the platform saves teams between $50,000 and $90,000 in engineering costs.
The takeaway: Vibe coding was one of the clearest productivity inflection points of 2025, shifting software creation from an engineer-only activity to a rapid, language-driven prototyping capability accessible to managers and founders.
While not production-ready by default, its impact is already measurable in faster time to market, six-figure cost savings per prototype, and enterprise-scale ROI that makes experimentation cheaper, broader, and strategically unavoidable.
7. The MIT study discovered that 95% of enterprise AI applications still bring no impact
In August, MIT-backed NANDA initiative published the “The GenAI Divide: State of AI in Business 2025” report, with one finding particularly standing out.
According to the study, only 5% of enterprise AI pilots bring revenue, while most deliver little to no measurable impact.
You may have seen the MIT study that 95% of generative AI projects fail. I believe this. The challenge isn’t AI itself — it’s the ability to rethink workflows, redesign processes, and operate differently.
Mohamad Ali, SVP and Head at IBM Consulting
It’s a bold number, but the real story is subtler – and in some ways, more damning. The divide isn’t about model quality. It’s about how organisations wrap those models.
On one side sits a shadow economy of employees using ChatGPT, Claude, or Copilot on personal accounts – flexible, cheap, and immediately useful. On the other side sit enterprise AI projects – often custom-built or pricey vendor tools – that collapse under the weight of workflow fit, governance, and brittle, hard-coded logic.
Tony Seale, former Knowledge Graph Architect at UBS, founder of The Knowledge Graph Guys
But not everyone was on board. Several enterprise leaders called the study out on methodology blunders.
Dave Kellogg, Executive in Residence at Balderton Capital, pointed out an overlap of what NANDA presented as the solution to the problem (an “agentic web” for distributed AI with its own focus on building networking agents.
Kevin Werbach, a Wharton professor, highlighted that the 95% claim making headlines was never explicitly mentioned in the study. The closest possible claim is that 5% of respondents successfully implemented custom AI enterprise tools, but that conclusion is not anywhere near as far-reaching as “95% of AI pilots generate zero returns”.

One of the reasons the MIT study exploded so effectively was that its release overlapped with an underperforming release of GPT-5. As teams were disappointed with the lack of meaningful improvements in the model that marketed itself as a “pocket PhD”, the MIT study further strengthened these concerns.
The takeaway: Regardless of methodological debates, the MIT study succeeded in shifting enterprise AI conversations toward pragmatic deployment strategies. The heightened focus on clear use cases, reliable data infrastructure, and measurable business outcomes represents a healthy correction from earlier hype-driven adoption approaches.
8. Competition for top-tier AI talent got fierce
This year, AI engineers got celebrity-level treatment, with employment agents, lucrative salary packages, and intense competition from leading AI labs.
Meta’s all-in talent war
Both by the pace of hiring and the pay package generosity, Meta took the lead. In June, Zuckerberg’s team offered up to $100 million in sign-on bonuses to poach OpenAI employees. That same month, Meta acquired a 49% stake in Scale AI at a total price of $19.3 billion and had its founder, Alexander Wang, lead the company’s Superintelligence Labs.
Meta also attempted to acquire The Thinking Machines Lab for $1 billion – Mira Murati, the founder of the startup now valued at over $2 billion, shot down the offer.
Reportedly, Zuckerberg’s key goal was poaching Andrew Tulloch, a former Meta engineer who continued his career first at OpenAI and, eventually, at Murati’s startup. Despite initially turning down Zuckerberg’s offer, in October, Tulloch changed his mind and will be coming back to work on Meta Superintelligence on a $1.5 billion pay package.
If you can’t hire them, acquihire them
Meta was not the only big tech company making waves on the job market, but its competitors took a different strategy.
Instead of poaching top researchers from other AI labs, they strike deals with promising AI startups to add their leading engineers to their teams.
The Google-Windsurf $2.4 billion deal, confirmed in July, was the biggest licensing move of the year. The team behind Windsurf, a vibe-coding agent, was at the time in $3-billion acquisition talks with OpenAI, but the deal fell through.
Google’s counteroffer was not an acquisition but a licensing agreement and a move to poach Varun Mohan and Douglas Chen, the co-founders of Windsurf.
In September 2025, Windsurf was acquired by Cognition and, according to early reports, helped nearly double the company’s ARR.
For big tech, acqui-hiring AI researchers at up-and-coming startups is an intelligent way to keep growing as the AI talent pool is drying up.
But, for enterprise teams looking for reliable AI vendors, the “acquihire boom” unlocked a new fear: “What if the vendor we chose gets acquired?”
Historically, startups struggled to survive after their founders jumped ship. Adept, a robotics company that signed a licensing agreement with Amazon, doesn’t have a product yet and only has four people indicating it as their workplace on LinkedIn.
When shortlisting AI vendors, enterprise companies may need to consider pending acquisition talks. Some startups, like CVector, an industrial AI company, baked “We are not going anywhere” into their positioning and are using stability as a bargaining chip in customer talks.
The takeaway: The 2025 AI talent war turned top engineers into strategic assets, driving unprecedented compensation, aggressive poaching, and a surge in acquihires as big tech competed for a shrinking talent pool.
For enterprises, this shifted vendor risk calculus: technical excellence alone was no longer enough, and organizational stability became a decisive factor in AI partner selection.
9. AI became a national security asset
Now that AI is getting more powerful, world leaders are exploring its impact on defense and global economics.
Steven Adler, a former AI Safety researcher at OpenAI, highlights that AI is on track to become a massive force in the military by helping develop:
- New weapon systems: both the US and China are actively exploring autonomous and semi-autonomous military units, often described as intelligent “robot legions”.
- Advanced cyber operations: AI-driven attacks capable of targeting high-stakes systems such as power grids, financial infrastructure, or even nuclear command-and-control.
- Enhanced intelligence analysis: models that can synthesize fragmented signals intelligence, satellite imagery, and open-source data at speeds beyond human capacity.
- Upgrades to existing defense technology: including AI-based image recognition for UAVs, sensor fusion, and stealth optimization for aircraft and naval systems.
In 2025, global world powers took different approaches to integrating AI into global trade and military.
US: continued growth and focus on competition containment
With the release of DeepSeek, Qwen, Kimi-K2, and other Chinese models that now rival SOTA LLMs by performance and reportedly beat them in cost-effectiveness, the American superiority in the AI race started appearing less certain.
To counter the rapid pace of AI research in China, the US government responded with containment strategies and regulations.
In January, a few Chinese AI companies were added to the Entity List to enforce stricter controls over chip export and supply chain intermediation between the countries.
In April, the US tightened controls on the export of NVIDIA H20 chips to China to prevent its number-one geopolitical rival from building state-of-the-art LLMs on American hardware. In December, the US allowed chip licensing but with an added 25% export fee.
Simultaneously, US-based AI labs are closely working with the government to expand AI involvement in security and state management.
In January, the White House issued the Executive Order on Advancing United States Leadership in Artificial Intelligence Infrastructure.
It encourages federal agencies to assist in the development of data centers and energy sources necessary to sustain them, to make sure the US has the resources necessary to build large-scale AI systems.
In June, OpenAI won a $200 million contract for the US Defense Department for building custom models that help solve security challenges in warfighting and supply chain.
Anthropic followed the lead by making Claude available for purchase by federal agencies, launching agreements with national laboratories, and building custom Claude Gov models for national security applications.
China: focus on self-reliance and AI deployment for pragmatic goals
China’s 2025 approach to the AI race is built around ensuring autonomy in core technologies: chips, models, and computing power. The government responded to NVIDIA licensing restrictions with regulations that prioritized domestic AI chipmakers like Cambricon and Huawei over foreign suppliers.
To boost domestic chip manufacturing, China backed several incumbents in the sector (MetaX Integrated Circuits and Moore Threads) with valuation growth and got financial backing from the government and VC firms.
Similar to the US, China also zeroed in on maximizing data center capacity and exploring cheaper compute sources. In December, the government announced the “East Data, West Computing” strategy that plans a state-led build-out of data center clusters and computing hubs in the country’s western regions.
These data centers, coupled with an expanded power grid that enables cheaper electricity, will help process millions of generative AI workflows generated by Eastern China.
Europe: regulation and responsible AI use
Unlike other powers, European leaders decided not to adopt the “move fast” AI development strategy.
Instead, EU nations focused on enforcing hard regulatory milestones under the EU AI Act.

In February 2025, the European Commission issued formal guidelines clarifying prohibited AI uses and followed them up with detailed governance rules and obligations for general-purpose AI (GPAI) models.
Although this cautious stance might help make AI development more sustainable long-term, in the short run, it is hurting European AI innovation.
The State of European Tech survey found that 70% of EU-based founders find the current regulatory environment too restrictive. Others are leaving the region altogether – as was the case for a Dutch messenger company, Bird, that moved most of its business out of Europe due to strict AI regulation.
The takeaway: In 2025, global superpowers realized the need for state participation in AI development, but they are taking different paths to this goal.
In the US and China, governments are actively incentivizing AI development and signing massive agreements to build data centers. In Europe, regulation takes the lead, which helps protect the general population from deep fakes and privacy risks of AI misuse, but it is hindering AI innovation.
10. Concerns about the AI bubble grew stronger
One of the most pressing AI questions that came up in 2025 was: “Are we in a bubble?” Answering this question negatively became harder and harder when Sam Altman himself said he thinks so.
There are indeed multiple signs of the expectations of AI being blown out of proportion, and reasons to worry about what happens when our current technologies do not hit these benchmarks.
Concern #1: Circular financing
Looking into recent investments and partnerships in the AI landscape, it’s clear that billions in financing flows between a small group of companies.
Infrastructure vendors like NVIDIA or Oracle are investing in cloud intermediaries and AI labs like OpenAI, which then reinvest that capital back into chips, compute, and data center capacity. This creates a feedback loop that amplifies market momentum but also concentrates risk.
NVIDIA is wrapping up 2025 as Wall Street’s hottest company, but a closer look at its earnings reveals that 61% of Q3 revenue came from four customers. If these partnerships fall out, NVIDIA is at risk of losing a large fraction of its cash flow and taking millions of shareholders down with it.
Economists have also raised concerns about how this growth is being financed. Morgan Stanley estimates that about 50% of the total $2.9 trillion in AI investment is funded via debt financing. If the bubble bursts, global companies that sign billion-dollar debt contracts can dissolve, as did victims of the 2008 financial crisis.
Concern #2: Adoption lags behind the hype wave
There is a growing expectation-reality gap between the “inevitable AI adoption” agenda AI lab leaders are pushing in media and internal communications and the reality of fairly slow and incremental adoption.
The positive gains of enterprise AI adoption have been widely reported, but they are hardly comparable to the trillions of dollars that tech companies spend on AI infrastructure.
For enterprise customers, scaling AI organization-wide is still a challenge – only 30% of global teams surveyed by McKinsey say they are actively doing so. UBS, one of the leading investment firms in America, has publicly acknowledged this discrepancy, stating that “enterprise AI spend is moving slowly” and “ROI is less clear.”
Right now, market leaders are operating on the hope that the enterprise segment will eagerly adopt the latest technologies, but real-world data is not backing that assumption. Should enterprise demand for AI solutions stay tepid, key AI infrastructure spenders will find themselves between a rock and a hard place when justifying their billion-dollar capex.
Concern #3: Data center ambitions are triggering public concerns
AI labs’ scramble for new energy sources and computing power to keep training the next generation of SOTA models is sending ripples way beyond the AI or data market.
It’s estimated that increased data center build-outs will drive the total US electricity use from roughly 4% to about 12%. Such a steep rise in electricity demand will negatively impact American households, who will shoulder the burden of higher utility bills.
In response to the backlash from local communities, state courts may be forced to pause data center construction projects. In November, the court of Virginia ordered a halt to construction of the Digital Gateway data center. Similar interventions are likely as environmental, zoning, and energy concerns intensify.
Until these tensions are ironed out, the infrastructure spend AI companies are allocating into data centers will be threatened by the uncertainty of political and community-driven friction, further destabilizing the landscape.
The presence of these risks does not mean AI is a dead-end technology. Historically, periods of intense hype often precede durable transformation.
An MIT Technology Review article argues that it’s more accurate to compare the AI bubble to the dot-com era than to the subprime mortgage crisis of 2008. After the dot-com bubble burst, it still left us the Internet and a handful of promising incumbents (Google and Amazon) that defined the modern technological era.
The same may be true for the AI bubble. It’s possible that most AI startups on the market today are not equipped to live through the burst. However, a handful of better-positioned market leaders may become the driving force behind the next age of technological growth.
The takeaway: AI bubble concerns are justified. A: a meaningful share of today’s momentum is being driven by aggressive capital deployment, optimistic timelines, and concentrated bets that can unwind quickly if demand lags.
At the same time, the presence of froth does not negate the underlying trajectory. AI capabilities are already reshaping how software is built and discovered, and the post-correction landscape is still likely to leave durable infrastructure and a new set of “default” interfaces for the future web.
The bottom line
Although the second half of 2025 forced the AI industry to recalibrate its expectations, the year ia still a net positive. The end of GPT dominance in the LLM arena helps level the playing field. It keeps all AI labs focused on improving both technical capabilities and the experience of interacting with models.
The growing penetration of AI agents and vibe coding is the first step towards AI democratization. Though it’s not here yet, we may be looking at a future where building an AI platform will require minimal engineering talent.
There’s uncertainty as to where machine learning as a field should go next if LLMs really hit the ceiling. Researchers already have ideas – world models, neuro-symbolic systems, and cognitive architectures. It’s unclear which of those will power AGI, but ChatGPT itself was the product of a decade of research.
Our takeaway is: while we wait for AI research labs to figure out the path that takes us to AGI, team leaders and employees should focus on making the most out of the tools they have.
Most organizations have barely begun to scratch the surface of custom-made AI agents, intelligent copilots, and predictive analytics. Applying these tools will be transformative for nearly every team, and by the time AI agents in the workplace become commonplace, the next frontier may arrive.