From the outside, payments feel instantaneous. A tap, a click, a swipe, and the money moves. But underneath, modern payment platforms are powered by intricate data engineering systems tasked with making this illusion of simplicity possible. Behind every authorization, fraud check, reconciliation, and dashboard lies a complex pipeline that must perform flawlessly and at a global scale.
In this article, we break down the five foundational data engineering challenges that shape the infrastructure of today’s leading payment processors and gateways, from Stripe to PayPal to Adyen. We’ll also explore how these companies are solving them with real-world case studies and why mastering these challenges is now a competitive necessity.
Core data engineering challenge #1: Extreme transaction volume and velocity
The most immediate and fundamental challenge for payment processors is handling the sheer scale and speed of transactions across global systems. Billions of transactions must be ingested, processed, authorized, and logged in real time. often within a sub-millisecond latency window, while supporting fraud detection and fault tolerance at a planetary scale.
Every transaction, whether it’s a micro-purchase on an app or a large cross-border transfer, demands near-instant decision-making. To meet this, platforms must ingest and analyze petabytes of transactional and contextual data daily, maintaining sub-millisecond latency as a baseline expectation.
That scale is not just theoretical; it’s backed by staggering numbers that illustrate just how immense and relentless this flow truly is. Consider the numbers:
- Stripe: In 2024, Stripe processed an astounding $1.4 trillion in total payment volume, marking a vigorous 38% year-on-year growth. This represents countless individual transactions flowing through their systems moment by moment.
- Visa: Visa’s Q1 2025 total transaction volume soared to $3.937 trillion, a testament to the continuous, global stream of payments requiring validation and routing.
- Mastercard: Mastercard commanded an astonishing $9.757 trillion in total transaction volume for the entirety of 2024, illustrating the monumental data throughput required.
- PayPal: PayPal managed $1.5 trillion in total payment volume in 2023, processing approximately 41 million transactions every single day. Peak events, such as Black Friday 2018, saw PayPal process over $1 billion in mobile payments alone, pushing data pipelines to their absolute limits.
- Adyen: Adyen’s processed volumes in 2024 reached an impressive €1,285.9 billion (approximately $1.3 trillion USD). During the 2024 Black Friday/Cyber Monday period, their platform processed over $34 billion in transaction value globally, hitting peaks of over 160,000 transactions per minute.
- Klarna: Even the relatively newer players demonstrate this accelerating scale: Klarna’s gross merchandise volume hit $93 billion in 2024, processing around 2.5 million transactions daily.
- Afterpay: Afterpay’s Gross Payments Volume (GPV) reached $8.24 billion in Q3 2024.
What makes this data problem uniquely difficult
- Billions of transactions daily with millisecond-level SLA
- Fraud signals span device telemetry, merchant history, and behavioral patterns
- Systems must remain available globally with high fault tolerance
Proven engineering strategies
High-throughput real-time streaming architectures
High-throughput real-time streaming architectures (Apache Kafka, Apache Flink) to ingest and distribute transaction data in near real-time. These architectures ensure that transaction data is captured at the point of origination, ingested in sequence, and forwarded for real-time decision-making, whether for authorization, fraud checks, or routing. This architecture is not just about speed, but consistency, resilience, and the ability to adapt to bursty, unpredictable loads during peak events like Black Friday or Singles’ Day.
Distributed low-latency databases
Distributed low-latency databases (e.g., Cassandra, HBase) for real-time lookups and transaction updates. These systems are essential for handling queries that must return results in milliseconds, supporting applications from fraud checks to transaction verification. Their scalability and resilience ensure reliability during traffic spikes, even under peak conditions like Black Friday.
Advanced fraud detection pipelines
Advanced fraud detection pipelines feed real-time data into ML models for scoring and blocking fraud within milliseconds. These pipelines combine streaming data, historical patterns, and contextual signals to enable rapid decision-making. They are frequently updated to adapt to evolving fraud tactics, ensuring platforms remain ahead of threats.
In-memory processing
In-memory processing (e.g., Redis, Hazelcast, Aerospike) for immediate access to risk factors. In-memory layers are used to store high-value, frequently accessed data like risk scores, recent transaction flags, and velocity checks. Their ultra-low latency enables instantaneous decision-making that traditional disk-based systems can’t match.
How leading payment platforms use real-time data engineering to power fraud detection and transaction speed
Visa and Mastercard exemplify this challenge with their AI/ML-powered fraud detection engines like Visa Advanced Authorization and Mastercard Decision Intelligence. These tools operate on top of real-time streaming architectures, often Kafka-based, that ingest and process transaction data within milliseconds. Their systems are backed by distributed NoSQL databases and in-memory compute layers to ensure sub-second risk assessment and scoring. Mastercard, for instance, publicly emphasizes its investment in AI for real-time fraud prevention, which rests entirely on high-performance data engineering. Visa builds its infrastructure to support millions of transactions per second while feeding models with clean, contextual data in real time.
PayPal faces similar velocity constraints. Their engineering teams have developed vast ingestion pipelines to aggregate data from transactions, device signals (e.g., via Fraudnet and Magnes), and behavioral events. These streams feed into real-time deep learning models for dynamic fraud detection and adaptive rule setting. Their Fraud Protection Advanced platform combines historical intelligence with live inference to block suspicious activity before it settles.
Stripe, processing over $1 trillion in annual volume, built its own internal document database, DocDB, on top of MongoDB Community. This system serves over 5 million queries per second across 5,000+ collections and 2,000 shards. Optimized for performance and availability, Stripe’s infrastructure resembles an in-memory DBaaS in behavior, with petabyte-scale data distribution and sub-millisecond lookups. These decisions ensure that authorization, fraud checks, and ledger updates complete reliably and in real time, despite the complexity of Stripe’s global ecosystem.
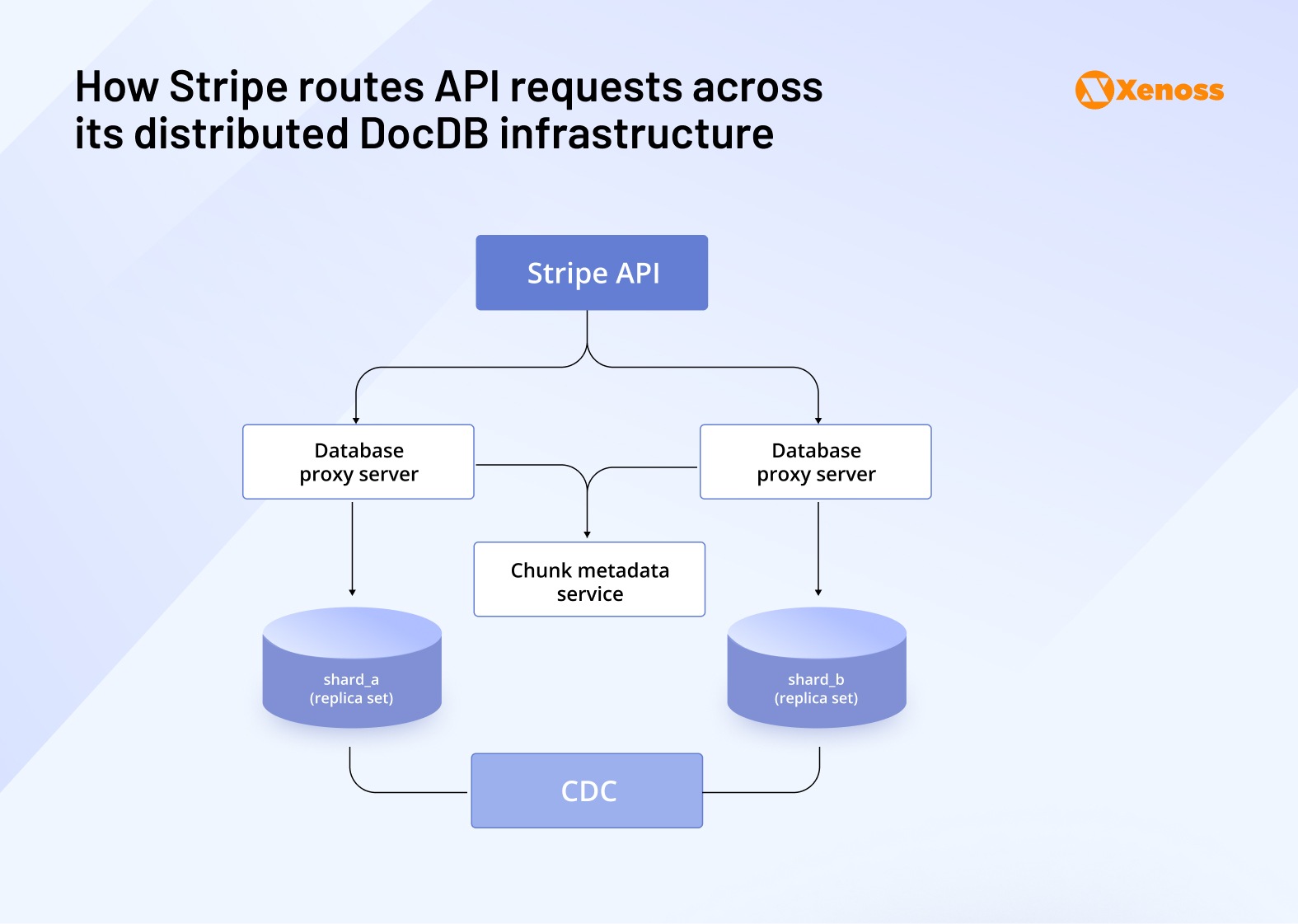
Core data engineering challenge #2: Building developer-friendly infrastructure with accurate and accessible data
Modern platforms like Stripe are known for their seamless developer experience, but delivering accurate, developer-facing financial data at scale is an engineering feat in itself. For platform-centric payment providers, the challenge lies in creating an infrastructure that is not only robust and scalable but also easy for developers to integrate with. This involves handling diverse transaction types, supporting recurring payments, and ensuring impeccable data quality for internal analytics and detailed merchant reporting, given the varied data inputs from different integrations.
What makes this data problem uniquely difficult
- Businesses demand trustworthy, queryable data for billing, accounting, and forecasting
- Internal and external stakeholders expect API-level access to near-real-time reporting
- Financial data must comply with global regulatory standards and be audit-friendly
Proven engineering strategies
Scalable and reliable ETL/ELT pipelines
Scalable ETL/ELT pipelines using Spark and Airflow with strong validation and schema enforcement. These pipelines are engineered with strict data contracts to enforce schema consistency and robust error handling across a multitude of merchant integrations. Stripe, for example, uses Airflow extensively to orchestrate Spark-based pipelines at petabyte scale, powering data products across 500 teams. Their scalability is critical for accommodating the growing volume of transactions and data transformations in real time.
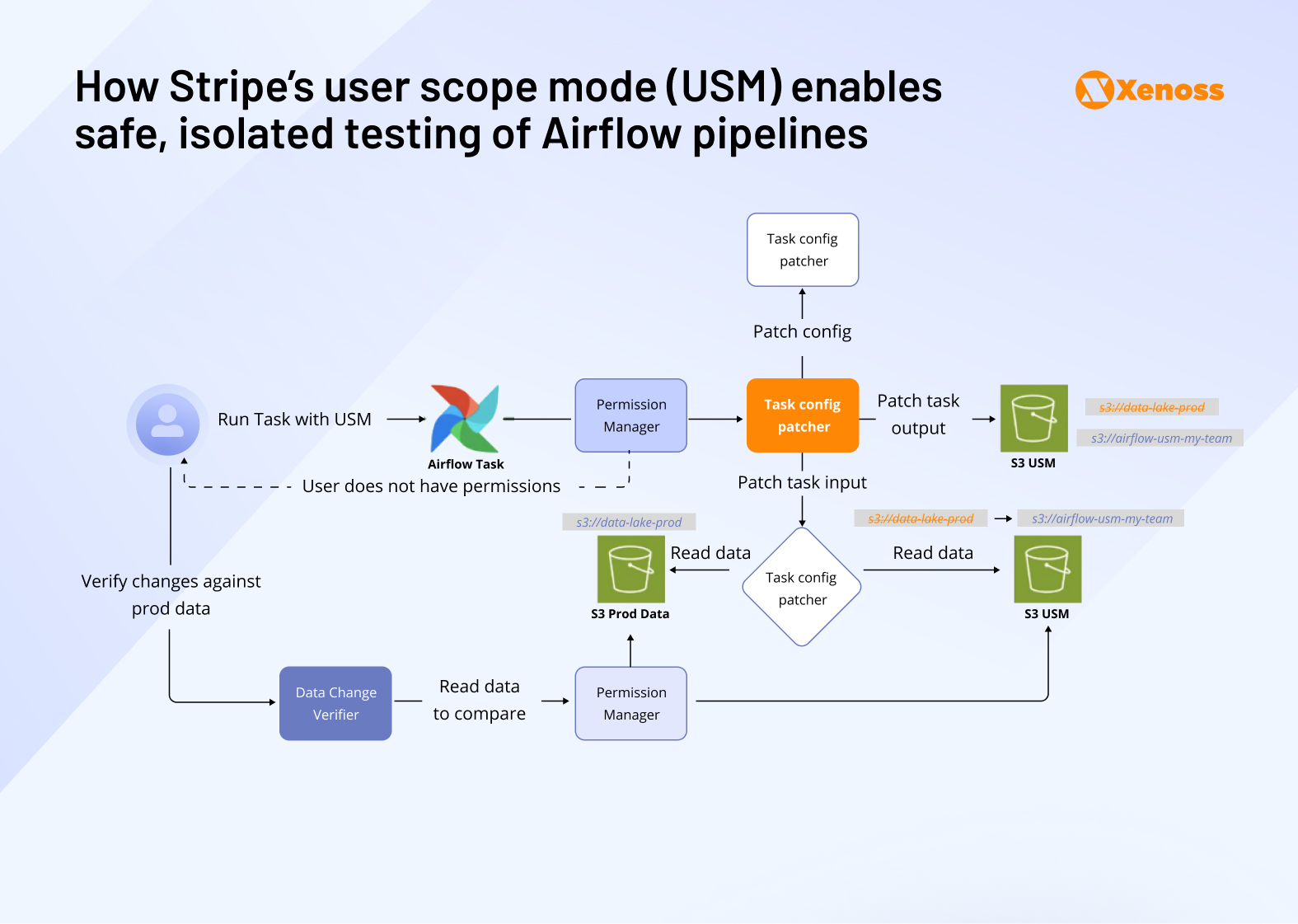
Robust internal data models and APIs
Robust internal data models and APIs that mirror public APIs for consistent internal analytics access. This alignment ensures internal teams (data scientists, finance, operations) can query payment data with the same structure and expectations as external developers, minimizing translation errors and accelerating product iteration.
Automated financial reconciliation systems
Automated financial reconciliation systems to ensure accuracy across currencies and payment methods. These systems reconcile payment flows, bank settlements, and merchant balances automatically, offering granular transparency and reducing manual overhead.
End-to-end governance and observability
End-to-end governance and observability: lineage, validation, and proactive issue alerts. Tools such as lineage tracking and alerting dashboards enable engineers to pinpoint and resolve discrepancies early, ensuring reporting systems stay reliable and audit-ready.
Real case: Stripe’s platform-driven approach to accessible financial data
Stripe’s developer-first reputation isn’t just a product of clean APIs; it’s underpinned by a deeply engineered data infrastructure designed to provide real-time, accurate, and accessible financial data at scale. A flagship example of this is the Stripe Data Pipeline, which allows users to sync Stripe’s payment, billing, and financial records directly into Amazon Redshift with no custom ETL work or data duplication.
This pipeline is built as a scalable, fully managed system that automatically shares near-real-time data updates across accounts using RA3-powered Redshift data sharing, eliminating the latency and complexity typically involved in financial data replication. The architecture below illustrates how this works in practice: Stripe’s Redshift environment shares data directly with a customer’s Redshift instance, which can then run federated queries across additional sources like Amazon S3, RDS, or Aurora, and visualize results through Amazon QuickSight.
This setup enables internal teams (like finance or ops) and external developers to access the same structured, queryable data, complete with schema guarantees and low-latency updates, for tasks ranging from cash flow forecasting to customer cohort analysis.
Core data engineering challenge #3: Supporting small business ecosystems with unified views across products
From POS to payroll to loans, SMB-focused platforms like Square serve as operating systems for small businesses. This creates complex, cross-product data relationships that must be unified to deliver actionable insights.
What makes it difficult is that data is often fragmented across systems: POS, ecommerce, lending, and more all operate on distinct schemas and timelines. Stitching these streams together is complicated further by product-specific data models, siloed metadata, and non-uniform integration standards. On top of that, SMB customers demand real-time visibility, self-serve dashboards that deliver holistic insights into sales, cash flow, employee performance, and customer loyalty.
Proven engineering strategies
Unified data platforms
Unified data platforms (data lakes/lakehouses) integrating structured and semi-structured data across services. These centralized systems, hosted on cloud platforms, ingest and store raw and processed data from all product lines, such as POS systems, e-commerce platforms, lending products, and payroll services. The result is a scalable repository that enables holistic analysis of SMB behavior, financial health, and engagement across all service touchpoints.
Flexible schema evolution
Flexible schema evolution and federated identity systems to connect user records across domains. Designing adaptable data models is essential when managing input from disparate product lines. Schema flexibility allows the platform to incorporate new data types quickly, ensuring smooth product rollouts without re-engineering data infrastructure. Federated identity solutions ensure that a single customer’s footprint, spanning purchases, employee payments, and loan applications, can be unified across previously siloed systems.
Real-time streaming pipelines
Real-time streaming pipelines for live sales, inventory, and cash flow insights. These pipelines power dashboards for merchants and internal teams alike. They aggregate transactional and behavioral data to enable merchants to act on trends as they emerge, spotting low inventory, tracking peak sales hours, or adjusting staffing. For internal product teams, these same pipelines surface usage insights, powering A/B testing and prioritization decisions across feature sets.
Cross-product risk scoring pipelines
Cross-product risk scoring pipelines for SMB-specific loan underwriting and fraud detection. By linking behavioral signals across tools, like how consistently a merchant processes payroll, how quickly they replenish inventory, and how seasonal their sales are, data teams can craft underwriting models tailored to the volatility and opportunity inherent in SMB ecosystems. Fraud detection systems, in turn, benefit from a broader understanding of merchant behavior beyond transactions alone.
Case in point: Block’s unified data platform for SMB analytics and risk scoring
Block, a company serving small and medium-sized businesses (SMBs) with platforms like Square, faced significant data challenges due to the fragmented nature of data from its various products (POS, e-commerce, lending, payroll, etc.). These diverse product lines resulted in different data models and schemas, making it difficult to achieve a unified view of SMB health.
To address this, Block leveraged Databricks’ Unity Catalog and implemented engineering solutions centered around unified data platforms, specifically data lakes/lakehouses. These platforms integrated both structured and semi-structured data from across their services, enabling a comprehensive understanding of their SMB ecosystem. As part of this transformation, the company managed over 12PB of data and reduced compute costs 12× while improving governance.
Key to this unification were flexible schema evolution and federated identity systems, which allowed Block to connect user records across different product domains. Furthermore, real-time streaming pipelines were established to provide SMBs with live sales, inventory, and cash flow insights through self-serve dashboards. Block also developed cross-product risk scoring pipelines, crucial for SMB-specific loan underwriting and fraud detection, leveraging the unified data to mitigate risks and better serve their clients.
Core data engineering challenge #3: Enhancing customer experience through data-driven personalization at scale
Beyond payments and fraud, platforms are mining their massive historical datasets to personalize experiences, predict support needs, and recommend financial products.
What makes this challenging is the sheer depth and breadth of data involved. Payment platforms often maintain years’ worth of historical customer interactions, spanning behavior logs, transaction history, and customer support records. This massive dataset must be queried in real time, with latencies low enough to serve machine learning models and personalization systems on the fly. On top of that, the infrastructure must support continuous experimentation and frequent model retraining, often across millions of users, without disrupting performance or data integrity.
Proven engineering strategies
Large-scale warehousing
Large-scale warehousing (e.g., Snowflake, BigQuery, or Hadoop) plays a foundational role in modern customer analytics. These systems store petabytes of structured and semi-structured data, including years of transaction histories, device metadata, and behavioral records. This long-term repository enables teams to run deep cohort analyses, train complex ML models, and generate holistic user profiles that drive strategic decision-making across product and marketing.
Real-time behavioral pipelines
Real-time behavioral pipelines (often built on Kafka) continuously stream customer interaction data, from clicks and scrolls to payment selections and device logins, into personalization engines. These pipelines are engineered to process high-velocity signals with millisecond latency, enabling dynamic content delivery, fraud mitigation, and behavior-triggered alerts in real time. The ability to act on live data significantly improves responsiveness and user engagement across platforms.
MLOps infrastructure
MLOps infrastructure supports the end-to-end lifecycle of machine learning for customer experience. This includes not only training and deploying models but also robust monitoring, feature store management, and automatic retraining pipelines. Whether it’s recommending tailored offers, setting dynamic prices, or routing support queries, the MLOps layer ensures that personalization engines evolve continuously and operate reliably in production environments.
Robust A/B testing infrastructure
Robust A/B testing infrastructure underpins a culture of experimentation. This infrastructure integrates deeply with frontend delivery and backend analytics systems, enabling granular measurement of customer behavior across variant experiences. By tying experimentation data directly into warehousing and ML feedback loops, teams can validate hypotheses faster, reduce guesswork, and build features that demonstrably improve outcomes.
Graph technology
Graph algorithms are increasingly vital for fraud detection by analyzing complex relationships between entities like users, accounts, transactions, devices, and IP addresses. Unlike traditional relational databases, graph technologies excel at revealing hidden connections and patterns, which is crucial for identifying sophisticated fraud rings and behaviors that might otherwise go unnoticed. They enable financial institutions to understand the context of activities and behaviors, such as tracing money laundering schemes or identifying synthetic identities that combine real and fake information. Graph algorithms can quickly uncover anomalies, predict future fraud, and reduce false positives.
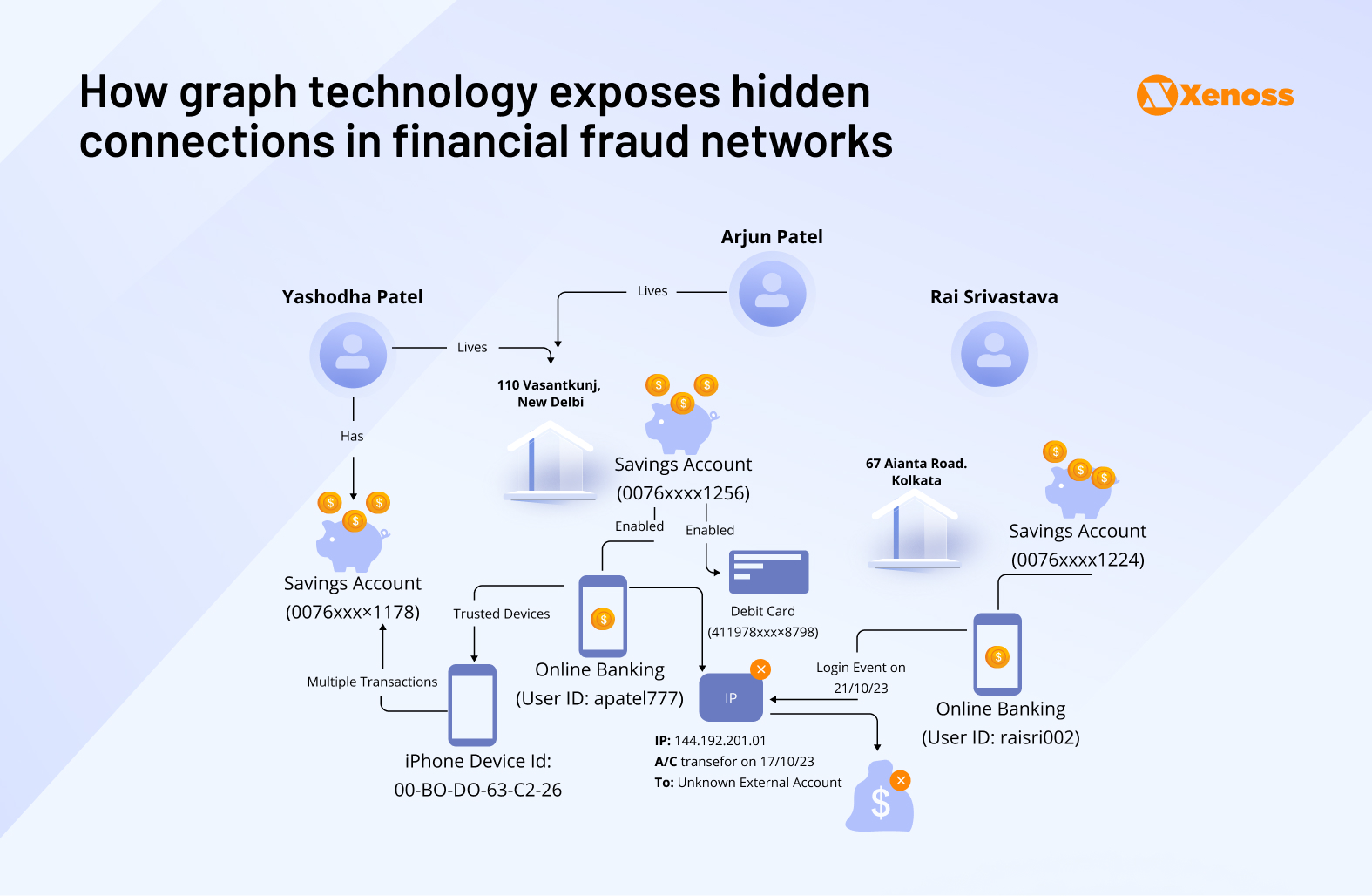
Case study: PayPal and graph technologies for fraud detection
PayPal, a pioneer in online payments, leverages real-time graph databases and graph analysis extensively to combat fraud, saving hundreds of millions of dollars. Their approach moves beyond traditional rule-based systems and isolated data analysis to focus on the interconnectedness of data.
One key application involves asset sharing detection, where PayPal builds an “Asset-Account Graph” to identify unusual sharing patterns. For example, if multiple accounts share the same physical address, phone number, or device, it can indicate a coordinated fraudulent scheme. By linking accounts to shared assets, PayPal can quickly identify abnormal linking behaviors and investigate suspicious clusters.
Furthermore, graph databases allow PayPal to easily extract and analyze complex transaction patterns that are difficult to identify with traditional relational databases. For instance, the “ABABA” pattern, where users A and B repeatedly send money back and forth in a short period, is a common indicator of account takeover (ATO) fraud and can be quickly identified through graph analysis.
Graph features like “connected community” help identify closely linked accounts and their transactional behaviors. This is particularly useful for detecting fraud rings, where a group of fraudsters might exhibit very different transactional connections compared to legitimate users. By understanding the structural characteristics of the graph, PayPal can identify “risky elements” (vertices or edges) and prevent large-scale losses.
Crucially, PayPal’s real-time graph database capabilities enable it to connect different relationships in near real-time, supporting its fraud detection activities. This allows for immediate action against fraudulent activities, such as blocking new accounts created by banned users. While primarily for security, this also contributes to a smoother customer experience by reducing false positives and improving trust. Data engineers build the underlying data platforms that allow for analyzing aggregated, anonymized customer data to drive these personalization efforts, ensuring a more intuitive and rewarding user journey. PayPal utilizes technologies such as Aerospike for underlying data storage and Apache TinkerPop with Gremlin as their graph compute engine and query language. This infrastructure allows them to process massive amounts of interconnected data with millisecond latency, enabling their machine learning models to make swift, informed decisions to protect customers and transactions.
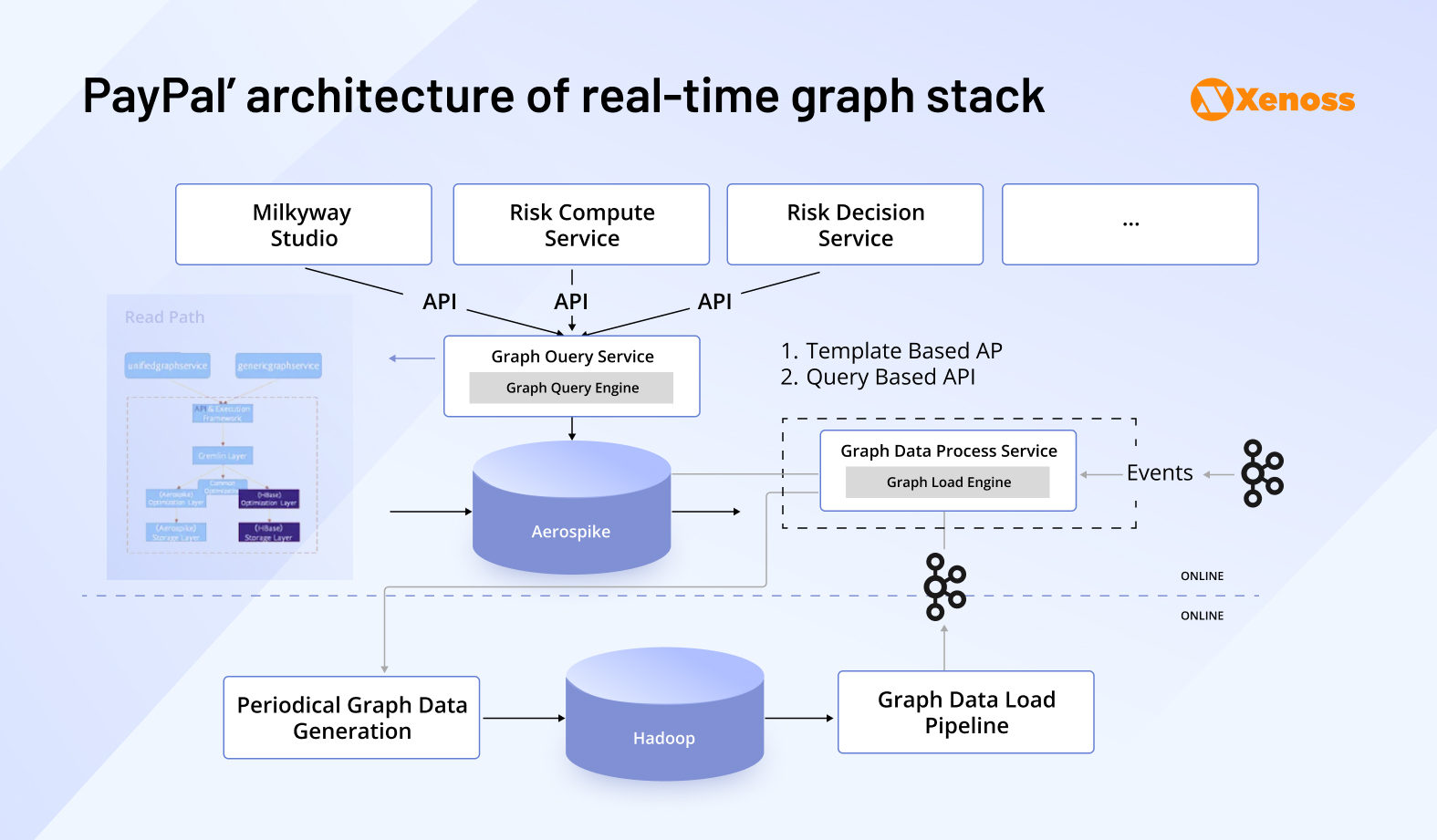
Core data engineering challenge #4: Operating a unified global payment platform with flexible architecture
Building and operating a truly unified global payment platform, supporting hundreds of payment methods across continents, means reconciling billions of data points while maintaining compliance with ever-changing regulations. This level of scale brings unique architectural burdens: systems must not only handle large volumes of heterogeneous data but must also normalize those flows across disparate schemas, currencies, and regulatory formats. Furthermore, accuracy and timeliness of reporting become paramount, especially as platforms span multiple business units and legal entities. Adding to the complexity is the requirement to maintain robust, compliant pipelines for global KYC and AML efforts, ensuring that identity verification and risk scoring adapt to each jurisdiction while still operating under a unified data backbone.
Proven engineering strategies
Centralized data hubs with universal connectors
Centralized data hubs with universal connectors serve as the backbone of global payment data platforms. Data engineers are tasked with designing systems that can ingest massive volumes of payment data from diverse sources, ranging from local PSPs to acquirers and digital wallets, and normalize it into a consistent, analyzable format. To achieve this, teams often build a comprehensive library of universal connectors that are capable of integrating with a multitude of proprietary APIs, legacy banking systems, and country-specific payment protocols.
Canonical data models
Canonical data models are developed to provide a unified view across all transactions, regardless of their origin. These models abstract away regional nuances, such as differing settlement timelines, field schemas, or local regulations, enabling downstream systems to reason about payments uniformly. Flexibility is key; these models must continuously evolve to accommodate new payment types, emerging markets, and regulatory mandates, while still offering backward compatibility.
Multi-currency and time-zone aware reporting engines
Multi-currency and time-zone aware reporting engines are critical for supporting the financial needs of global merchants. These systems must handle real-time currency conversion, daylight saving adjustments, and regional tax considerations, all while producing accurate and auditable reconciliation data. Timeliness is essential, especially when financial reports need to be generated on a daily or hourly cadence across multiple business units or jurisdictions.
Dynamic routing and real-time analytics
Dynamic routing and real-time analytics allow platforms to intelligently direct transactions to the optimal acquiring bank or payment rail, maximizing authorization success rates and minimizing fraud. Data engineering teams build streaming analytics systems capable of scoring transactions in-flight, leveraging historical success data, real-time risk signals, and contextual merchant behavior. This dynamic decision-making infrastructure requires ultra-low-latency pipelines and the ability to update routing logic in real time as new patterns emerge.
Cloud-native and microservices-based architecture
Cloud-native and microservices-based architecture underpins the entire global payment infrastructure. Engineering teams leverage managed services for stream processing, serverless compute, and horizontally scalable storage to handle spiky workloads and regional deployment challenges. This modular approach ensures resilience, rapid iteration, and adaptability to local market demands and compliance regimes.
Case in point: How Adyen uses real-time data and graph models to power global payment intelligence
One platform that exemplifies these engineering principles in practice is Adyen, a global payment company operating in over 30 countries and supporting hundreds of payment methods. At the scale Adyen operates at, every decision about data infrastructure directly impacts authorization rates, fraud risk, and merchant trust. To meet these demands, Adyen has built a deeply integrated, intelligence-driven architecture that transforms raw transaction data into real-time insight and action.
At the core of Adyen’s system is a centralized data hub that ingests and processes thousands of events per second. Payment attempts, device fingerprints, shopper metadata, and merchant context all flow into a unified pipeline, orchestrated using Apache Airflow and transformed via PySpark. The goal isn’t just storage, it’s clean, validated, and canonical datasets that can be used across teams: risk, finance, machine learning, and compliance. By enforcing consistency early in the data lifecycle, Adyen reduces redundancy and ensures downstream systems speak the same language, whether they’re running an AML check or producing a reconciliation report.
But normalization is just the beginning. Adyen’s ability to act on data in real time is what sets it apart. To fight fraud and enable instant compliance decisions, Adyen developed an internal graph database system, engineered on top of PostgreSQL and Java, that maps relationships between transactions, devices, users, and behavioral signals. This graph layer enables the platform to detect fraud rings, trace suspicious onboarding flows, and score risk in milliseconds. When a payment attempt comes through, it’s not evaluated in isolation; it’s contextualized against a dynamic web of global interactions.
This real-time intelligence feeds directly into Adyen’s machine learning layer. Every transaction benefits from the platform’s AI-driven products: Adyen Protect, which blocks fraudulent activity in-flight, and Adyen RevenueAccelerate, which uses ML models to optimize authorization routing and retry logic. These models are trained on global payment flows and are constantly updated using fresh data from the centralized hub. According to Adyen, these optimizations have delivered measurable results up to 6% uplift in conversion and significantly lower fraud losses for merchants.
Behind these tools is a sophisticated ML infrastructure. Adyen has built a scalable feature platform, ingesting structured data from Kafka, Hive, and Spark, and serving features to models with sub-100ms latency. Their research teams also explore advanced techniques like off-policy evaluation, allowing them to test and iterate on recommendation algorithms without live traffic exposure, shortening time-to-insight and reducing the cost of experimentation.
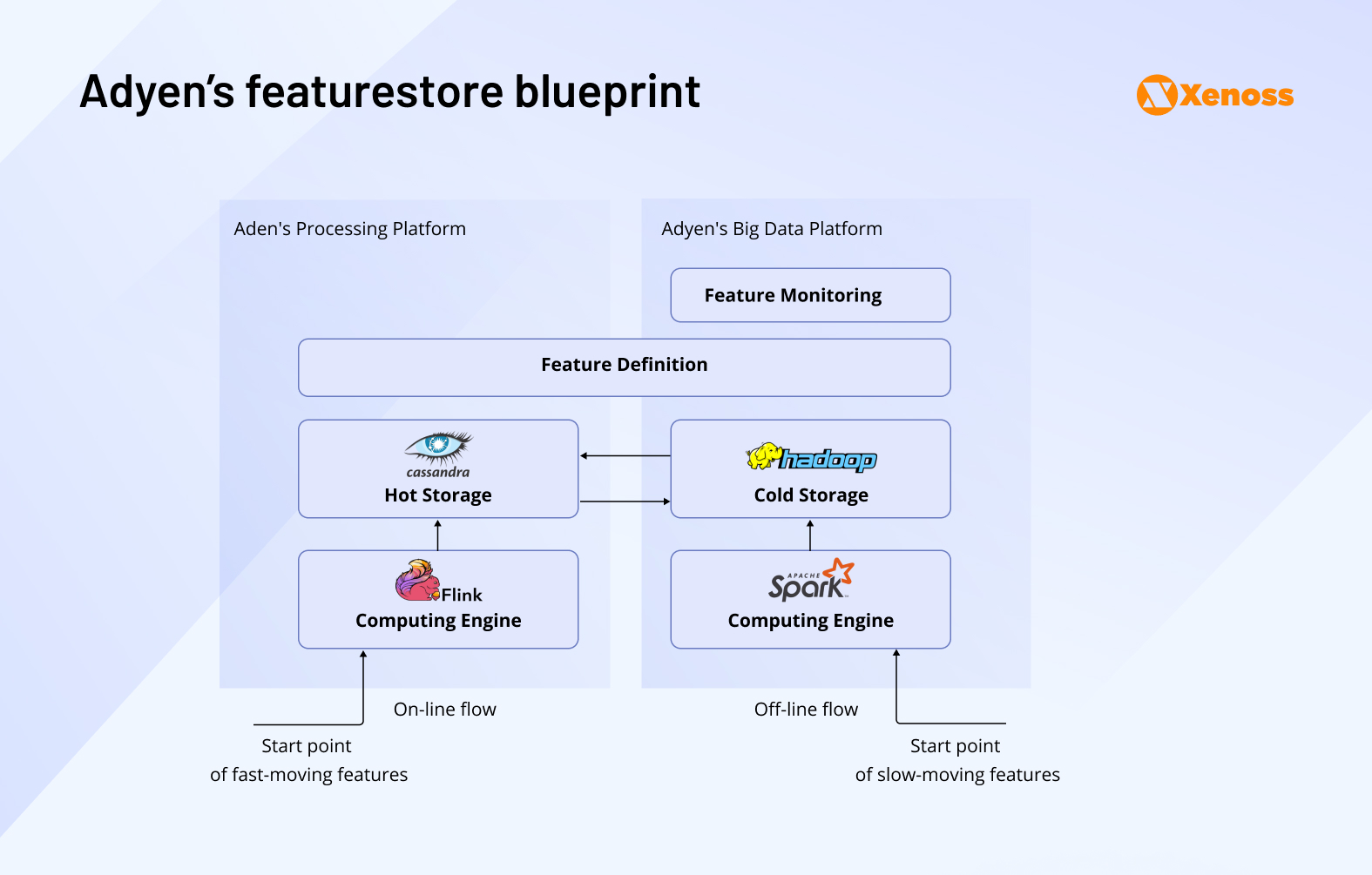
In short, Adyen’s data architecture doesn’t just scale, it learns, adapts, and informs every facet of its global payments engine. It’s a striking example of how a modern payment company can transform the chaos of real-time, multi-jurisdictional transactions into a coherent, intelligent system. Through canonical modeling, centralized ingestion, and embedded ML, Adyen shows what it truly means to operate a unified global platform with flexible, resilient, and forward-looking architecture.
Final thoughts
From fraud to reconciliation to global scale, modern payments are a data engineering challenge disguised as a financial service. The winners in this space, from Stripe to PayPal to Adyen, aren’t just good at money. They’re masters of infrastructure.
And if you want to compete, you need to be too. Xenoss can help you get there.
How Xenoss can help
Building this kind of system internally takes years. Xenoss specializes in helping fintech companies engineer:
- Real-time streaming architectures for fraud detection and authentication
- Resilient, schema-flexible ETL pipelines across global payment rails
- Cloud-native ML infrastructure with online/offline feature stores
- Auditable, compliant data lakes and warehouse strategies


