Cookie – a two-bit, lightweight data file invented in 1994 – remains the lifeline of the AdTech industry today. Not for much longer, though.
Safari and Mozilla dropped third-party cookies years ago. Google was planning to shut cookies down by the end of 2024 but has taken a U-turn on its timeline and further delayed the deprecation.
Although the urgency of the cookieless transition in the AdTech community waxes and wanes, it’s apparent by now that the future is cookieless, and the full cookie sunset is just a matter of time.
An important question publishers should consider is: What will a cookieless Internet look like, and which cookieless alternatives will emerge on top?
In this article, we explain:
- why third-party cookie depreciation is happening
- what Google Privacy Sandbox is, how it affects AdTechs
- how user ID graphs and universal IDs can become a new interoperability mechanism for the industry
- what stands behind the buzzed data clean room solutions
- if contextual advertising should be considered among third-party cookie alternatives
- why digital fingerprinting is a huge no-no
- what the pros and cons of different cookieless tracking solutions are
- how to implement cookieless tracking
- what the optimal way forward is for the AdTech industry
Why are third-party cookies being deprecated?
For years, the AdTech industry has relied on third-party cookies as a straightforward data exchange mechanism.
Cookies allow capturing extensive user data:
- interests and browsed items
- user geo-location
- language preferences
- time spent on site
- past browsing behaviors
The drawbacks? Third-party cookies can also be invasive and breach consumer privacy laws such as the European GDPR and California’s CCPA in the US.
Despite regulatory requirements, 55% of publishers did not offer an option to tailor cookies’ consent settings proactively. Such lax treatment led to further investigations and fines. Big Tech firms like Amazon, Google, and Meta also paid lip service to the compliance requirements.
Under mounting regulatory pressure, Google announced the “Privacy Sandbox” initiative, designed to deprecate third-party cookies in Chrome and Android devices and implement more privacy-centered ad solutions.
The 2020 announcement was a big blow to the AdTech industry. Stocks plummeted. Many AdTech development plans stalled.
Under pressure from advertisers and with regulators’ approval, Google extended the Privacy Sandbox timeline. Most APIs are already available for testing, but their performance is far from satisfactory.
In February 2024, IAB Tech Lab released a report commenting on the limitations of the Privacy Sandbox. It gradually became apparent that it would not become a full cookie replacement by the end of the year. CMA was not happy about Google’s progress either—at the end of the day, the company decided to take more time to improve its updates and address industry concerns.
What are the alternatives to third-party cookies?
Due to the high stakes created by the impact of cookieless future, the AdTech market came up with a spectrum of alternatives to 3P-based targeting.
With third-party cookies soon to be gone for good, AdTech software development must rapidly adapt to the cookieless future. Further, we will take an in-depth look at all of the cookieless advertising options on the table.
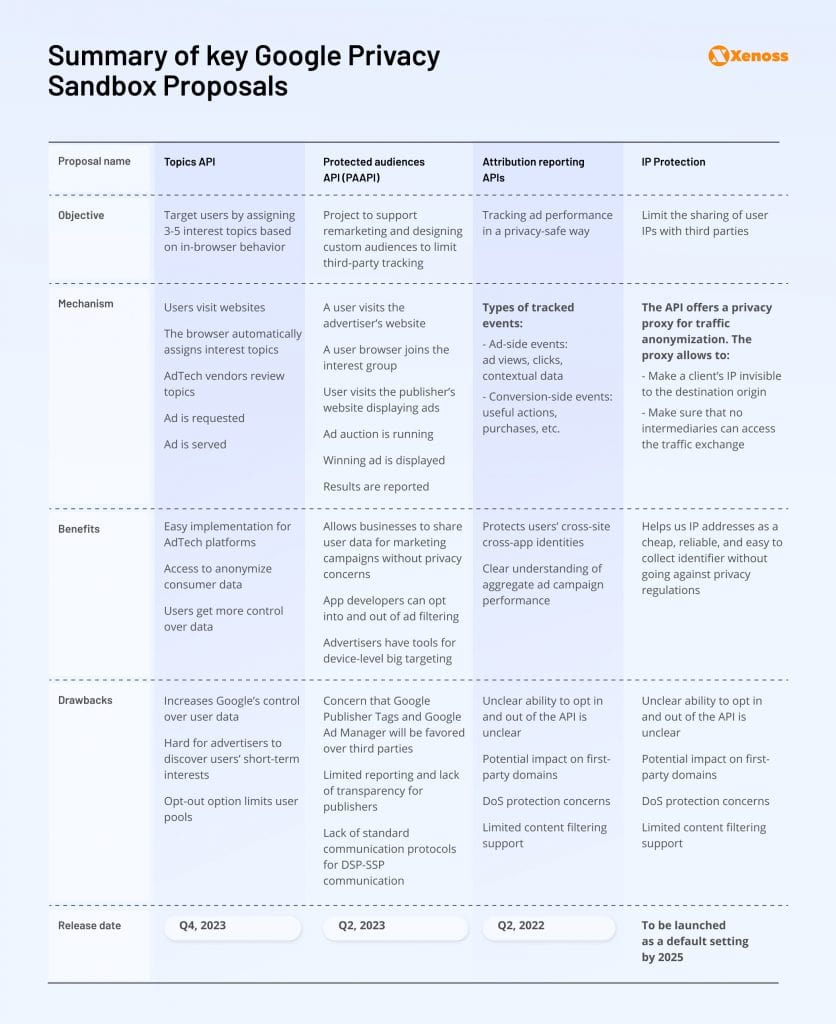
Google’s Privacy Sandbox
Considering that Google made over $237 billion on advertising last year alone, the tech giant cannot afford to be a bystander in the cookieless transition. Without an alternative cookieless solution, Google and its AdTech partners risk losing a ton of valuable tracking, attribution, and personalization capabilities.
Google is also under the regulators’ magnifying glass. To stave off regulatory action, Google developed the Privacy Sandbox – a new set of guidelines and technical means the company will use to improve user privacy, ad targeting, measurement, and fraud prevention.
General premises of Privacy Sandbox
- Elimination of third-party cookies and all cross-site tracking mechanisms.
- Willful IP blindness – proposal prohibiting servers from tracking user IP addresses and using them as identifiers.
- API-driven ad measurement and reporting where aggregated data is available without event-level visibility.
On paper, these ideas seem adequate. In practice, they were hard to implement. The AdTech ecosystem spoke about Privacy Sandbox harshly: Jeff Green, CEO of The Trade Desk, told Digiday that pushing forward with the proposal would be “a strategic mistake” for Google.
To understand why publishers and advertisers raise eyebrows at Google Privacy Sandbox, let’s quickly recap the most talked about proposals and related concerns.
User identity graphs
User ID graphs (also known as user knowledge graphs) are comprehensive customer profiles, built with cross-correlated first-party data. Essentially, ID graphs attempt to create an ever-evolving view of the particular user across every touchpoint around the web, then exchange this data with other ecosystem partners.
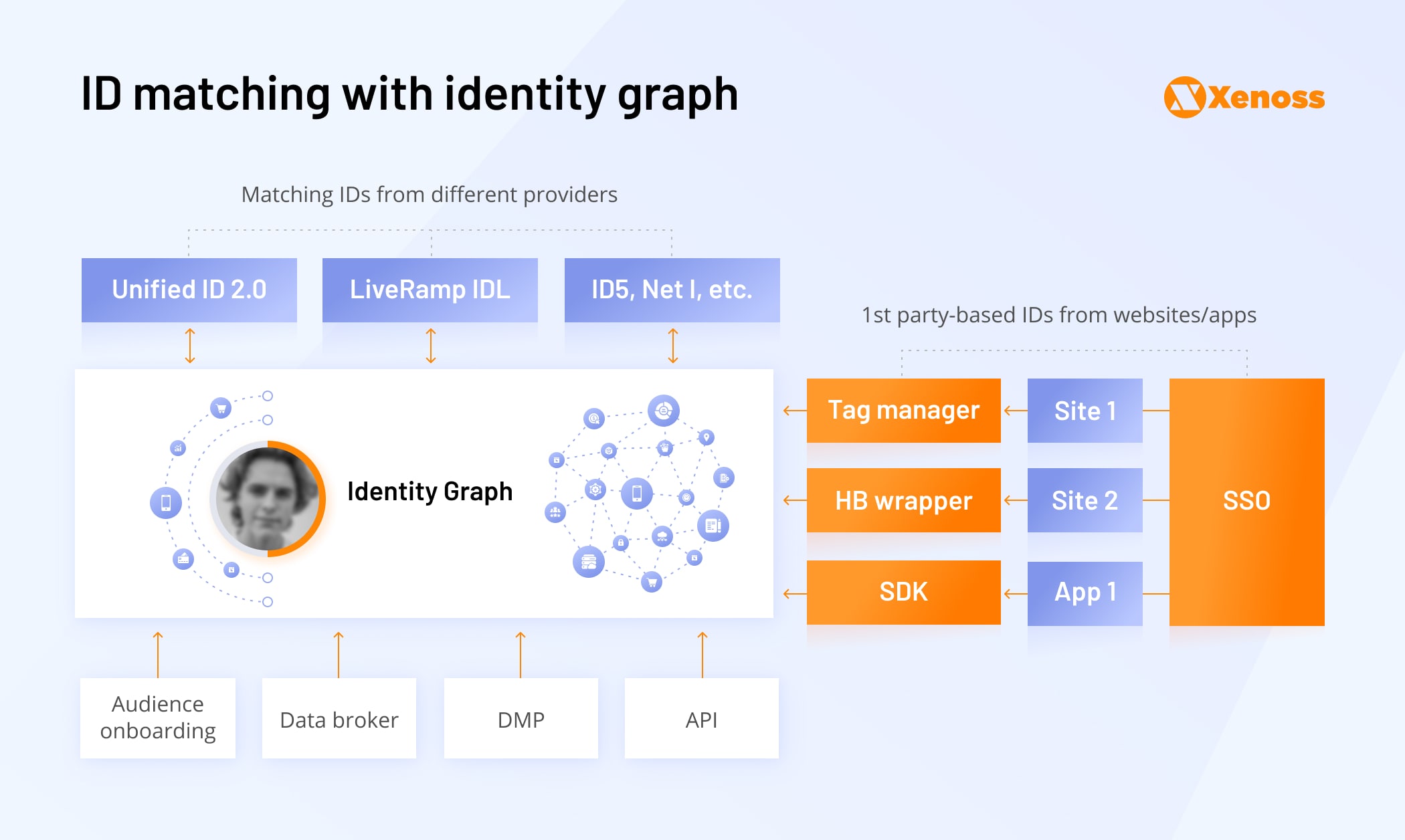
ID graphs can include:
- anonymized PII
- cookies-based data
- offline data
A scalable identity graph solution can manage connections between billions of identities with minimal latency. The goal: reconcile the brand’s and publisher’s knowledge of users. Then employ it for high precision targeting and programmatic ad auctions (conducted via DSPs).
To cross-correlate data, ID graph solutions use two matching methodologies (or a combination of them):
- Deterministic matching relies on verified, validated data points, often supplied by users directly in the form of email, name, phone, known devices, etc. Deterministic matching can be email-based, device-based, or tied to different data points, known to be true and accurate (e.g., person’s loyalty card + name + telecom data from a linked device).
- Probabilistic matching employs predictive algorithms to cross-match individual pieces of information and develop a user ID. For example, device OS, IP address, and purchase history on a website. Using this mechanism, you can extrapolate that a phone and a laptop, linked to the same Wi-Fi network and location used during the day belong to one household.
Probabilistic matching is less precise, but it enables:
- Extended reach by identifying more devices, belonging to deterministically identified people
- Linkage curation by reconfirming deterministic identification and resolving identity conflicts
Use identity graphs can be also paired with universal ID solutions (more on this in a bit!) to enable cross-ecosystem data exchanges.
Below is an overview of popular ID graph solutions.
Tapad
The Tapad Graph is a device-based ID solution. Tapad uses customer-supplied data to create initial deterministic IDs, then cross-correlates them across multiple devices to learn which ones belong to the same person or household.
To date, Tapad mapped over 4 billion users to 1.3 billion devices using over 1 trillion data signals. They work with both first-party and third-party data (for now). Using Tapad, advertisers can get a new layer of customer knowledge for ad measurement, targeting, and personalization across devices.
Partnerships:
Tapad has premade integrations and data exchange partnerships with the following players:
Verizon Media Next-Gen solutions
Back in 2020, Verizon Media launched a Connected ID – a user ID graph, based on some 200 billion data signals, generated across Verizon-owned consumer brands and telecom data. It’s a deterministic-based solution. All user ID data is obtained with consent and in a privacy-complaint way.
In 2021, Verizon added probabilistic matching capabilities and branded the new offerings as Next-Gen Solutions. The team added extra data signals from its media networks such as weather, location, device type, and user behavior metrics, to create Next-Gen Audiences.
Next-Gen Audiences are powered by Verizon’s machine learning model, trained on first-party data signals. By aggregating demo, interest, income, look-alike, and predictive audience signals, it supplies brands with accurate user knowledge.
Advertisers can now choose to use:
- connect ID service if they have a user ID or
- opt for Next-Gen audiences without relying on any identities.
Next-Gen audiences are now part of Verizon Media DSP (Yahoo AdTech). The company also developed a new measurement mechanism to provide accurate reporting on ROAs.
Verizon also partnered up with Catalina, a CPG shopper intelligence platform, to obtain extra data signals for user ID graphs and improve measurement capabilities.
Partnerships:
Verizon ID solutions integrate with the following platforms and publishers:
LiveRamp ID
LiveRamp has also been building a robust identity infrastructure, allowing brands to create first-party-based IDs using multiple data points.
Their infrastructure has two components:
- Authenticated Traffic Solution (ATS) – a privacy-focused, content-driven user authentication solution, that brands and publishers can employ to collect first-party user data. Some 215 publishers and 25 SSPs worldwide have adopted ATS.
- RampID (former IdentityLink) – a determinative, people-based user ID graph.
LiveRamp positions itself as the largest deterministic identity graph on the market with PII accumulated from 245 million Americans.
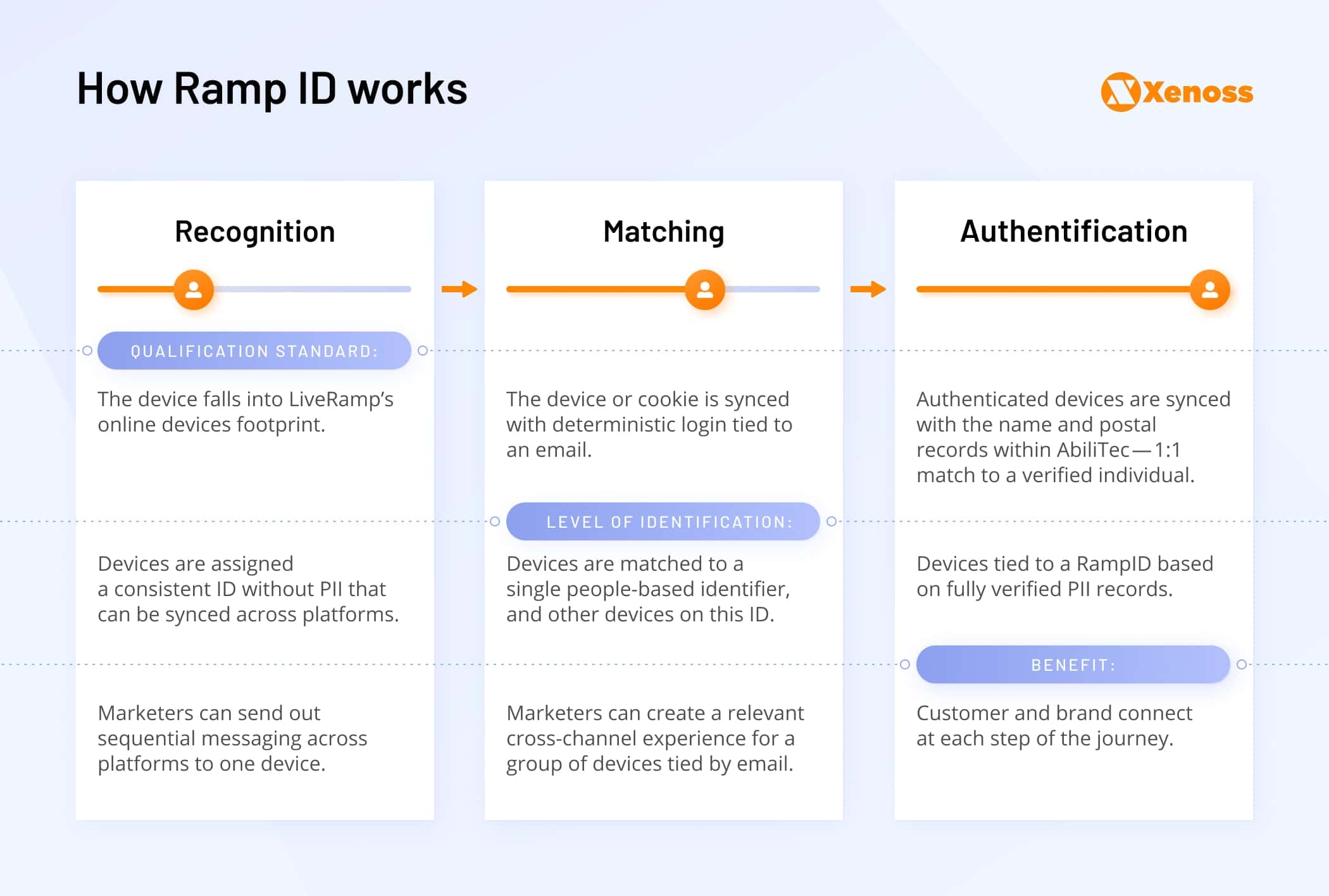
In 2020, LiveRamp partnered with The Trade Desk to join its universal identity development efforts.
This partnership enabled buyers to bid on The Trade Desk with Ramp ID and maintain measurement across multiple environments – desktop, mobile, and connected TV. Essentially, brands can maintain effective attribution, measurement, and ROI without any third-party cookies or device IDs. Publishers, in turn, can also maintain high CPMs and demonstrate better ROAs while ensuring high consumer privacy.
Main benefits of user ID graphs
- Access to compliant, first-party data based user profiles for advanced targeting and programmatic ad campaigns
- High scalability potential with multi-device and multichannel reach
- Multiple types of user ID solutions available on the market
- Precise, cross-environment measurement and attribution
- Capable of real-time personalization and dynamic, context-sensitive creative
Major drawbacks of user ID graphs
- Privacy concerns around ensuring proper PII anonymization and cross-device correlation. User ID graphs can face similar regulatory concerns to what FLoC had — too precise and too invasive.
- Email-based user IDs or device-based IDs may not be a reliable foundation for assembling user identities. Emails may also be seen as a sensitive data signal by regulators.
- The initial costs to create first-party-based user IDs are steep. AdTech companies will also need to join forces to ensure accurate data matching, fast ID resolution, and prevention of ID conflicts.
Universal ID solutions
Proposals for a universal ID emerged in response to a surge of independent user identity graphs.
Universal ID proposes to hash users’ personal identifiable information (PII) into a readable 32-digit-long string of numbers, which can then be exchanged between players without breaching privacy. It’s a tokenized standard for enabling interoperability between different user ID graphs.
The idea for universal IDs was first pitched in Project Rearc by IAB Tech Labs. The group proposed several ways forward in the post-cookie world:
- Seller-defined audiences (SDA) — a technical specification for securely exchanging first-party data between publishers, data management platforms (DPMs), and other data providers without relying on cookies or mobile IDs
- User-enabled identity tokens — an open-source tokenization framework and set of best practices for creating user-enabled IDs — then exchanging them within the ecosystem for targeting, measurement, and personalization
User-enabled identity tokens framework became the backbone for universal ID solutions, now developed by several players.
Unified ID 2.0 by The Trade Desk
Based on IAB guidelines, The Trade Desk developed an open-source Unified ID 2.0 solution. It primarily relies on hashed user email to enable interoperability and cross-ecosystem user identification. Though targeting can be enhanced via partner-supplied identity graphs data.
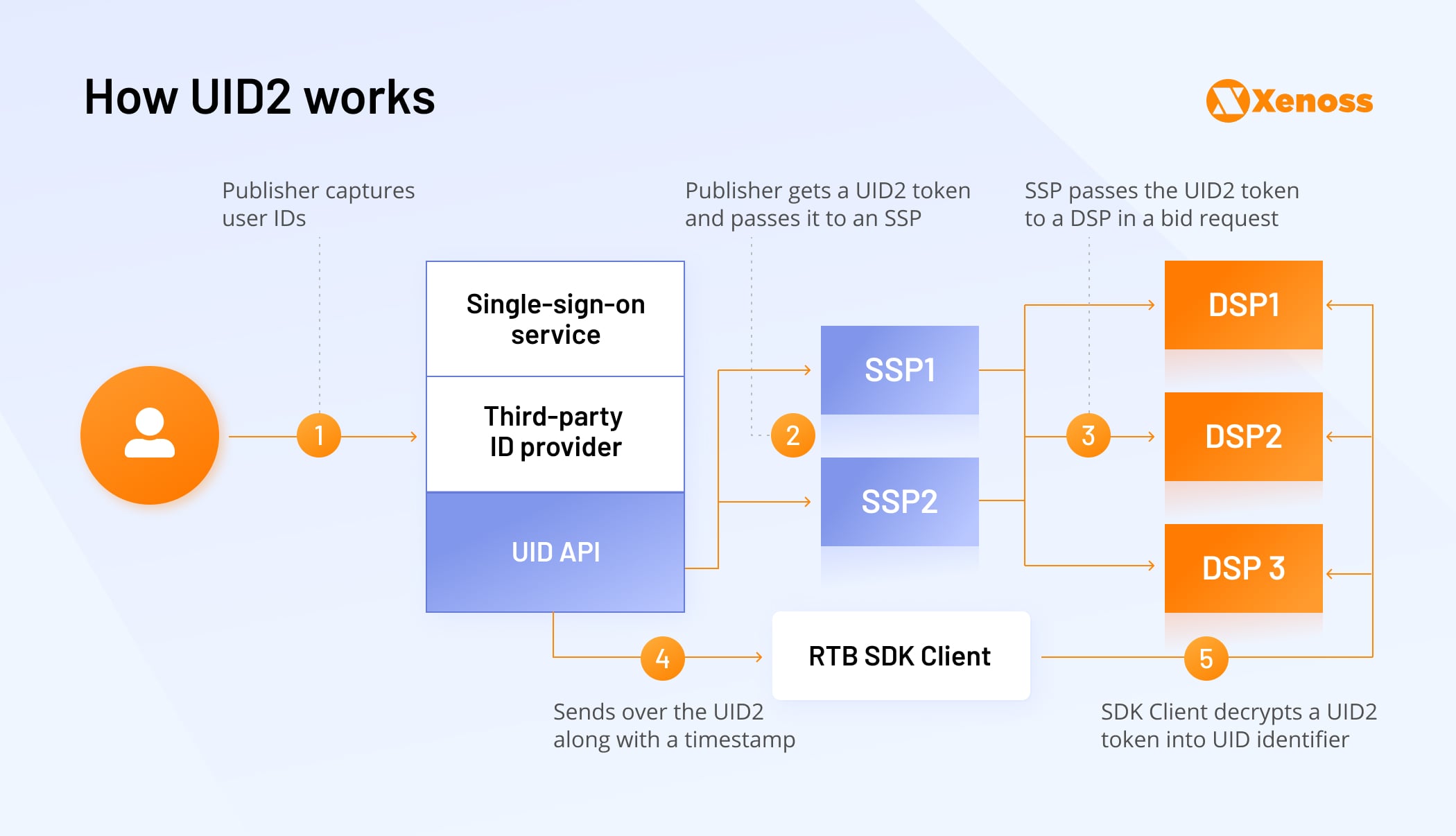
Here’s how UID2 works:
- Publishers can use a single-sign-on service or a partnering third-party ID provider (like LiveRamp) to capture user IDs or integrate UID2 API directly into their login system, then get a UID2 token and pass it to an SSP.
- Supply-side platforms (SSPs) will pass the UID2 token to a DSP in a bid request. The idea: have a mechanism where SSPs and DSPs can use a decrypted UID2 token like any other identifier such as a cookie.
- Demand-side platforms (DSPs) install a UID2 RTB SDK Client to decrypt tokens. Then register with UID2 Administrator to receive an authkey used to initialize the SDK. Once done, a DSP can call the SDK during RTB auctions to decrypt a UID2 token into a UID2 identifier. The SDK sends over the UID2 along with a timestamp of when a user first established the UID2 — and notifies if the token is expired. This mechanism allows DSPs to match audience data and conduct frequency capping. The DSP will also need to install a mechanism for honoring user opt-out requests, sent by the UID2 Administrator.
- Data management platforms (DMPs) and data providers will have to supply audience data based on UID2 to DSPs. The mechanics are similar to the way that data providers push data sets using a cookie or device ID. The DSP then reconciles UID2 in the pushed data sets with one present in the incoming bid request to target users.
Despite being a technically complex solution, unified ID 2.0. is the current front-runner for cookieless targeting. It has substantial industry support from major players.
- Criteo is working with The Trade Desk on SSO technology for collecting user email addresses for a Unified ID 2.0.
- LiveRamp already integrated its authenticated identity infrastructure (ATS + RampID) with Unified ID 2.0. Recently, the two also announced plans to build a European Unified ID (EUID) solution for GDPR-compliant ad targeting.
Other UID2 supporters include:
- SPPs
- Mobile ad platforms
- Ad exchanges
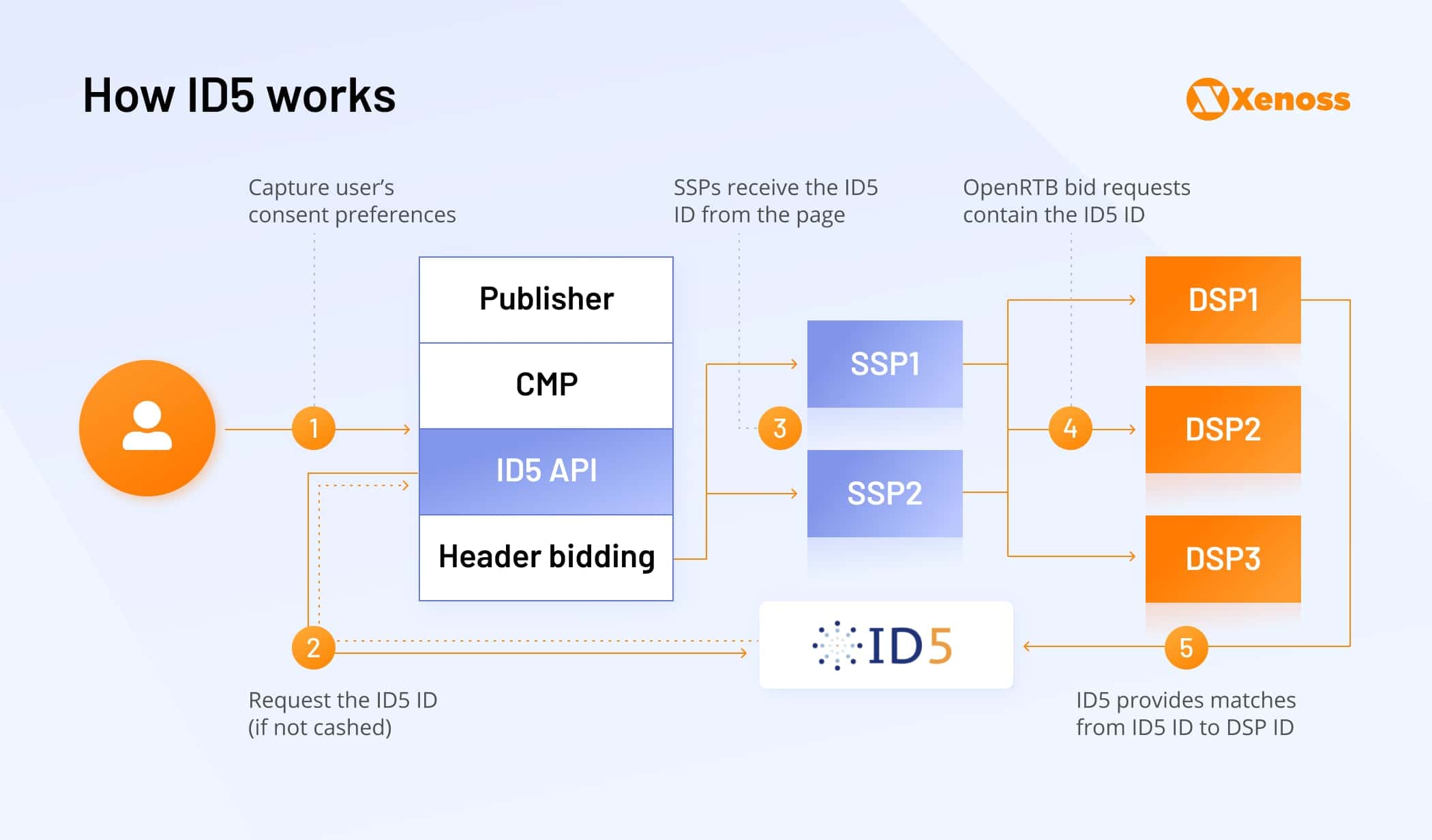
ID5 Universal ID
ID5 Universal ID is an alternative project, led by identity services provider ID5. Unlike UID2, ID5 wants to use multiple soft signals including IP address, user agent, page URL, page referrers, etc., combined with first-party storage mechanisms to identify users for its shared ID solution.
Here’s how ID5 universal ID works:
- ID5 provides brands and publishers with a consent mechanism for capturing a user’s email address.
- The hashed email is then exchanged with SSPs and DSPs, using ID5 identity solutions.
- The main difference with the UID2 is that the ID5 universal ID already comes with an integrated ID Partner Graph and Cross-Device Graph
- Partner graph contains information on how ID5 IDs correspond to other platforms’ cookie-based user IDs and how these different platform user IDs relate to each other. In other words: They attempt to cross-correlate user IDs for as long as cookies data remains accessible.
- In the meantime, ID5 also trains a cross-device graph – an identity-less solution, built on soft data signals, obtained from users. The solution uses a similar mix of probabilistic and deterministic matching capabilities to Verizon Media Next-Gen Audiences or RampID.
As ID5 CEO Mathieu Roche explains:
Unlike other identity solutions that are focusing on authenticated users, we combine deterministic and probabilistic methods to increase the chances to provide publishers and brands with an ID. Authenticated users only count for a small percentage of the total addressable market. We think that as an identity provider we need to develop as many technical methods and capabilities as possible to identify consenting users, combining scale and accuracy to generate higher revenue opportunities.
ID5 Universal ID adopters include:
- DSPs:
- SSPs
- Data platforms
- Lotame
- Hive Media
- And others
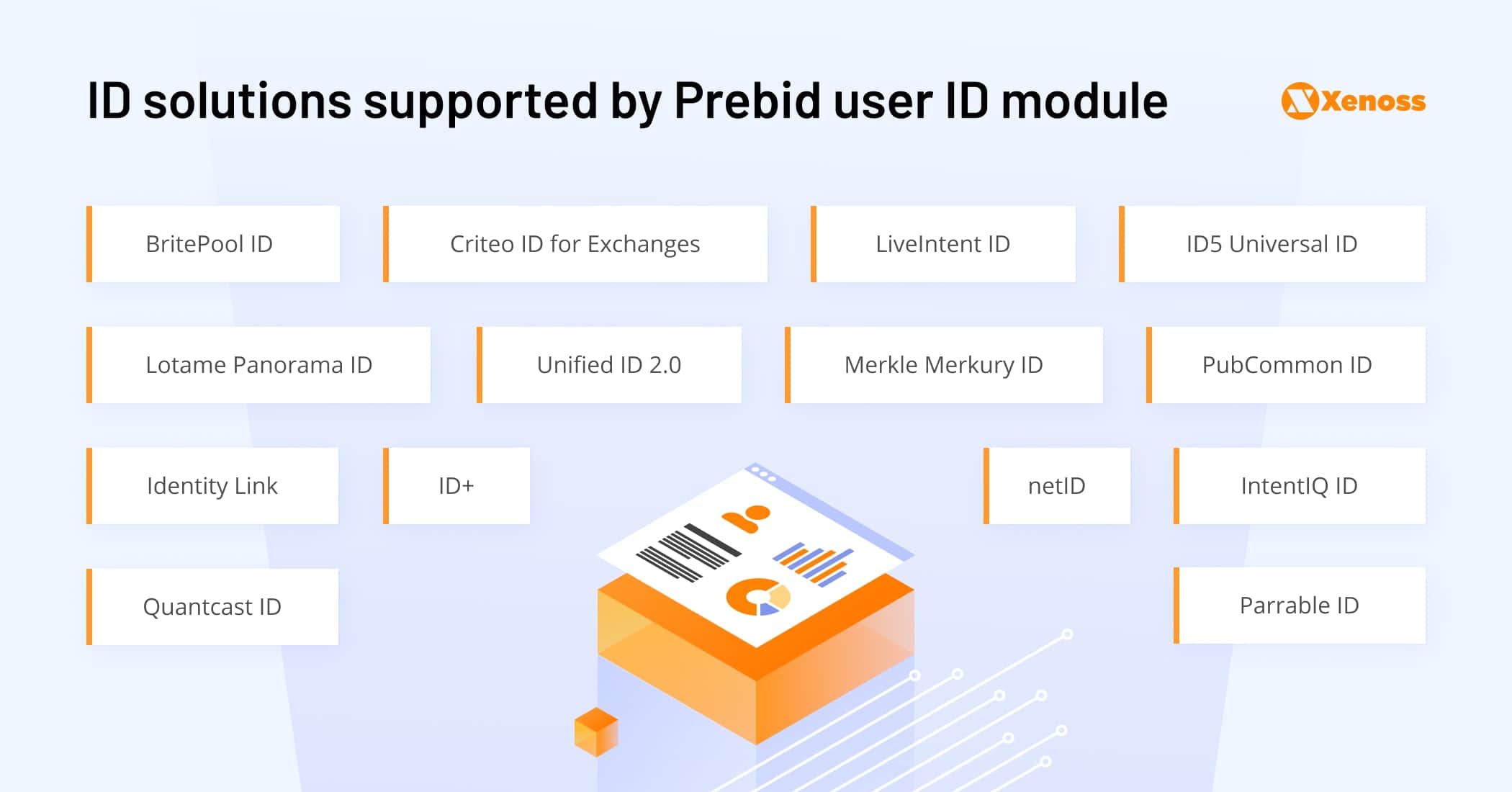
Prebid
Prebid.js was launched in 2015 to make header bidding more accessible for publishers – a job it did superbly. Prebid also grew to become an integral part of the universal ID industry. Its main pitch: create a simple mechanism for synchronizing various types of IDs to streamline header bidding.
That’s a noble cause because the volume of universal ID solutions (and the user identity graphs behind them) keeps growing – and this already creates interoperability issues.
Here’s how Prebid works:
- Prebid created a new User ID module type. Publishers can integrate it with different user ID solutions (proprietary or shared).
- A consent module is available to capture user information in a regulatory-friendly way.
- Once the right ID is captured, it can be passed along to an SSP, using one of the supported user ID solutions — and then further down the chain.
Prebid also participates in universal ID 2.0. project and it will act as an operator for the initiative. Prebid agreed to manage UID2 hardware and software infrastructure, handle email encryption/decryption process, and manage other ID controls. They also commit to keeping the project open source.
Benefits of universal IDs
- Front-running alternative to cookies synching for privacy-safe data exchanges within the AdTech ecosystem
- Low implementation barriers and the highest degree of interoperability, compared to other options
- Strong technical foundations and standardization principles proposed by IAB — and built up by leading players
- Allows advertisers to maintain demographics, geo, and behavioral targeting capabilities, instead of switching to interest-based targeting
Drawbacks of universal IDs
- Universal IDs are limited to the domain the user visits. Because of that, such project’s success rates strongly depend on the publishers. Most will have to implement email capture strategies – and perhaps even populate user IDs with extra data from their customer management platforms (CMPs). However, the scale of such solutions may not initially match third-party cookies.
- Establishing sweeping user authentication can pose challenges for publishers. Many users are opposed to giving away their emails – or provide “burner” accounts instead. Without robust DPMs and identity infrastructure, publishers will struggle to supply a steady stream of data-rich IDs for ad targeting and personalization. This would push some to develop custom user graph solutions or adapt existing ones, but the adoption speed might not be as fast as the industry hopes for.
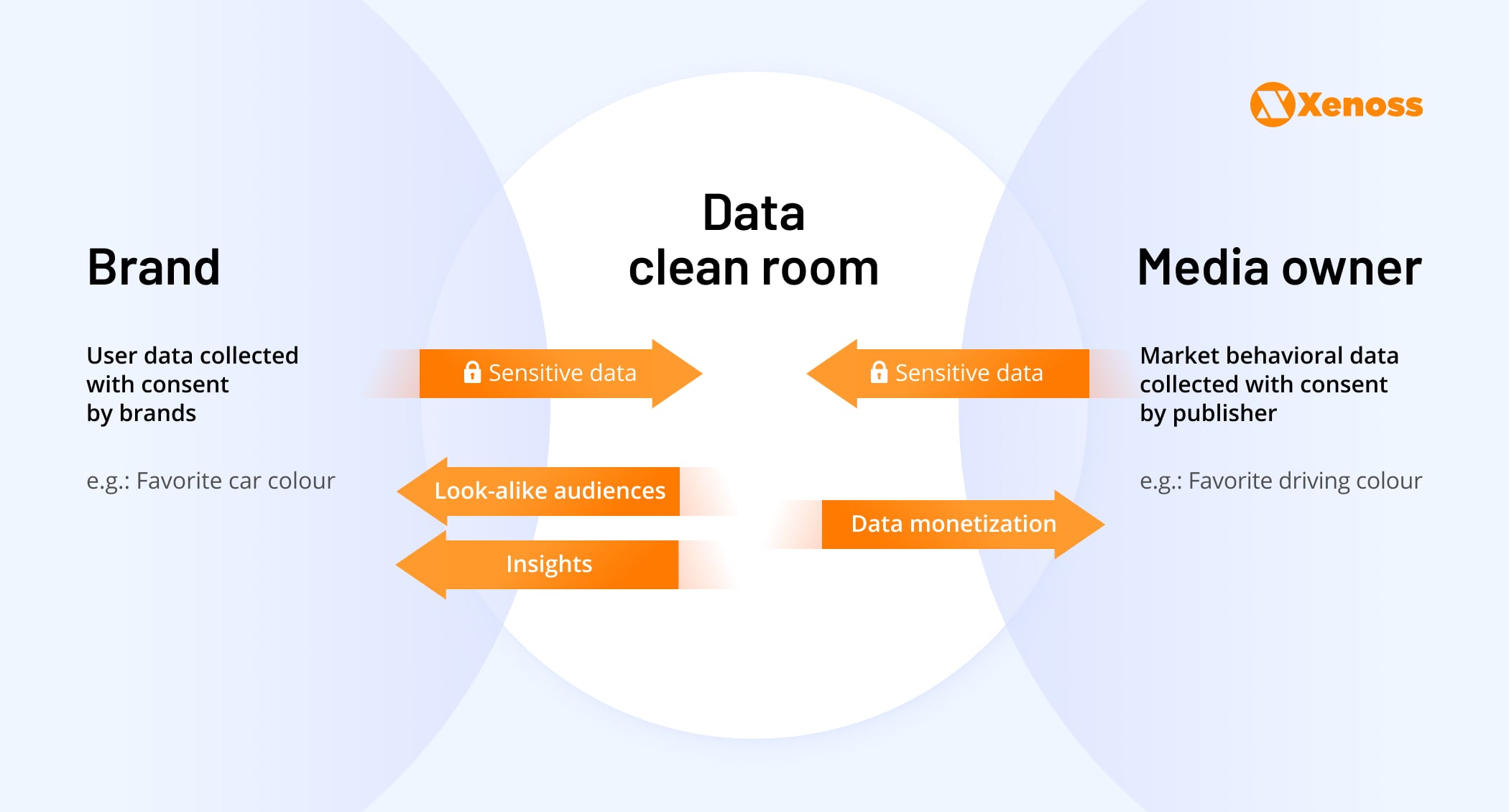
Data clean rooms
Data clean rooms originally emerged as a juxtaposition to “walled gardens” as spaces where brands and advertisers could host private exchanges.
Data clean rooms provide a secure data-sharing environment where publishers and brands can safely share, match, and activate data in a compliant way.
Data clean rooms are often referred to as the “Switzerland of data”, because two parties have access to a neutral zone. In this environment, users can use customer-level data as input while getting aggregated, non personal identifiable audiences as an output.
Jose Uzcategui, Global Lead at Ayudante, Inc.
As a publisher, you open up some audience insights to a retail brand and compare your audience knowledge. For example, consumers’ interests, demographics, products purchased, buying frequency, etc.
Data clean rooms can be used to
- measure campaign performance with high precision without breaching privacy laws and
- improve ad targeting and personalization based on the publisher-supplied, first-party data.
Both features appeal to brands — and are actively pursued by different players. Google’s Ads Data Hub (ADH) allows brands to join first-party datasets (for example, offline sales) with online campaign performance data to understand correlations in performance.
Amazon is said to be testing a data clean room to provide brands to link their insights to their advertising activity on the platform. Disney is working on a clean room together with Omnicom Media Group. Plenty of standalone data clean room companies also operate in the field.
InfoSum
InfoSum is a British data clean room company that offers real-time, first-party data matching, rapid identity resolution, utmost security, and nonnegotiable customer data privacy.
InfoSum is one of the few “closed operators” for UID2, authorized to use first-party data to create and encrypt UID2 identifiers. A UDI 2.0. integration also means that publishers can
- add first-party signals from InfoSum hosted data to a bid request sent to an SSP/DSP and
- easily connect their InfoSum identified audiences to The Trade Desk using UID2 identifiers.
Separately, InfoSum has a partnership deal with Adform. This way, Adform DSP users can easily use “clean room” data in programmatic ad campaigns.
Additionally, InfoSum partners with ActionIQ – an enterprise customer data platform – to supply verified, second-party data to clean room users.
Permutive
Permutive also supplies brands and publishers with the infrastructure for brokering secure data exchanges. They use a first-party cookie approach to help media networks develop better audience knowledge – and then securely share it with advertisers.
Their current partners include big names like Buzzfeed, Business Insider, Conde Nast, BBC, and SHE Media, among others. Permutive also integrates with AppNexus, The Trade Desk, Lotame, and Neustar Fabrick universal ID.
Habu
Apart from data clean room infrastructure, Habu provides a host of value-added features, including customer journey mapping and attribution, advanced segmentation, private activation, automated data discovery, and advanced data attribution.
They also recently partnered with Ibotta, a leading rewards platform, to supply users with second-party audience data. L’Oreal, Oasis, and Kroger are among the brands using Habu.
Benefits of data clean rooms
- Zero trust, privacy-safe method for advertisers and brands/publishers to cross-match user data and exchange insights
- Access to more audience and campaign performance insights without extra regulatory compliance
- Ability to build custom audience profiles, perform advanced user segmentation, and run other data modeling scenarios
Drawbacks of data clean rooms
- Limited scaling capacity. Data clean rooms remain more of a 1:1 solution – and an expensive one to implement. Consequently, only a fraction of brands would consider it.
- Lack of proper consent mechanism for collecting customer data. Some also worry about how brands and publishers would ensure content-based data exchanges and provide consumers with the right to request information on data usage or data removal.
- Data clean rooms don’t solve the “messy data problem.” Brands and publishers will need to figure out how to de-silo, cleanse, and transfer the right data to the clean room.
- Conflicts of interest. If an ad network operates a data clean room, the integrity of the performance and attribution data provided by the clean room itself is debatable.
Contextual advertising
As the name implies, contextual advertising adapts ad serving to the context, rather than to knowledge about users. It’s a huge industry, worth $227.38 billion in 2023 and projected to hit $562 billion by 2030.
For big-name publishers with diverse content verticals, contextual advertising is a proven way of generating revenues without being bothered with extra tech. The Washington Post and The New York Times have been using this technology for ages. Contextual targeting in CTV is a newer promising marketing vector.
Modern contextual advertising platforms can identify context through different lenses — semantics, video, and user behavior metrics, then provide advertisers with rich metrics for cookieless targeting, audience activation, and engagement.
Leaders in contextual targeting space:
- Contextual targeting suite by Criteo
- Ara TopicMap by Quantcast
- Semasio Unified Semantic Targeting
- Oracle Contextual Intelligence
Main benefits of contextual advertising
- No reliance on third-party cookies data or ID graphs with resulting easier compliance
- Faster AdTech platform development timeline and lower solution operating costs (compared to user ID graphs or data clean rooms)
- Higher brand safety with advanced context-aware blocklisting of unsuitable resources.
- Greater relevancy thanks to advances in natural language processing (NLP) technologies for running inventory assessments
Major drawbacks of contextual advertising
- Similar to Topics API, contextual advertising campaigns are interest-based, meaning you are more limited in terms of demographics, intent, and behavior-based targeting.
- Without reliance on cookies, user graphs, or other types of IDs, campaign measurement can be murky.
- Accurate frequency capping and precise attribution are hard (though not impossible) to implement.

Digital fingerprinting
Digital fingerprinting emerged among the first cookieless advertising solutions. And it’s now one with the worst reputation.
Similar to third-party cookies, digital fingerprinting solutions assign a unique ID to a user (or device) that can be cross-tracked across properties. This often happens on the server-side (not in the browser) via a third-party tracker.
For example, a mobile fingerprinting tracker can harvest data such as
- hardware type
- phone language settings
- time zone
- screen resolution
- battery status
- browser versions
- installed apps
- and more
The problem? Such tracking happens without the user’s consent or knowledge. Data regulators view digital fingerprinting as invasive and a breach of consumer privacy.
Researchers found that advanced digital fingerprinting can be used to identify a worrisome 99% of users (whose consent to data sharing wasn’t received). A 2021 analysis of browser fingerprinting practices also notes that a quarter of the world’s top 10,000 websites are running fingerprinting scripts. Some AdTech companies profit from this data, but it’s a slippery slope.
Safari, Firefox, and Chrome made updates to limit browser fingerprinting. Data regulators are also rumored to further clamp on device- and browser-based fingerprinting. So it hardly makes a viable alternative to third-party cookies.
Major drawbacks of digital fingerprinting
- Invasive and unethical tracking mechanisms are frowned upon by consumers and brands alike.
- Digital fingerprinting is on shaky legal grounds within the GDPR framework — and is the next target for regulatory action.
- Short attribution window. Fingerprints remain 98% accurate if matched within the first 10 minutes. Then accuracy drops to 80% during the next three hours – and plummets to 50% after 24 hours.
Main differences between cookieless solutions
To help you decide which cookieless advertising options you should pursue, here’s a high-level summary of the main pros and cons.

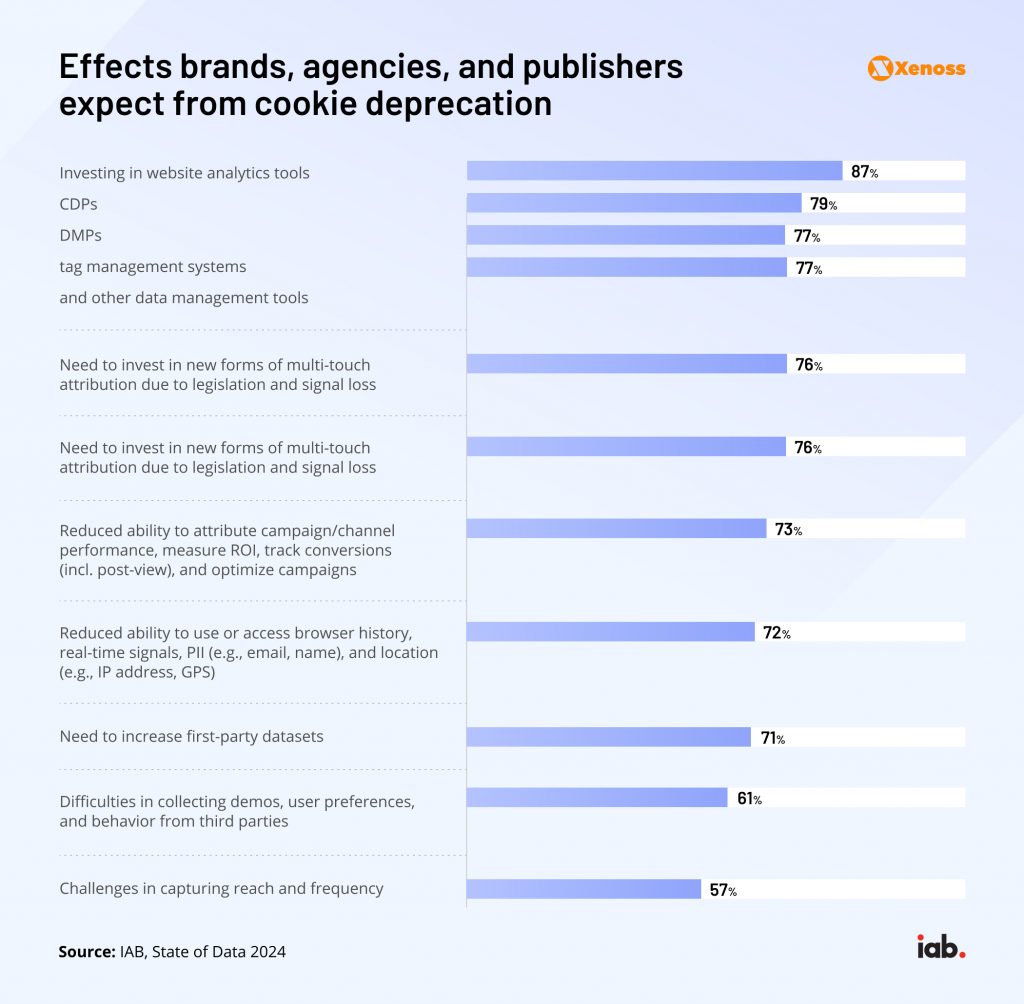
How to adapt to a cookieless future
The current options on the table aren’t equally appealing.
In its current state, Google Privacy Sandbox raises eyebrows from regulators. In the UK, CMA is concerned about the search giant monopolizing AdTech services and limiting advertisers’ and publishers’ control over their campaigns.
IAB Tech Lab also called Google out for not delivering on many use cases the industry now considers basic, such as support for exclusion targeting, creating custom audiences across several domains, and more.
In the near future, Google is expected to collaborate closely with regulators until it achieves functionality, a commitment to privacy, and the ability to not interfere with the free market.
Contextual ad targeting and various semantic solutions are good add-ons, but can’t replace cookie-based advertising either. Digital fingerprinting is a downright dangerous technique that is under regulatory crackdown.
Here’s how other industry players are responding:
Based on our extensive experience in the AdTech industry, the Xenoss team suggests the next algorithm for action:
- Customer data platform development for first-party data collection
- Partnership with a reliable provider or custom user graphs and data clean rooms (as an add-on)
- Integration with other ID graph solutions and universal IDs

First-party data and user intelligence become the new life-blood of the industry as browser- and device-supplied knowledge is fading out. Publishers who’ll be able to accumulate the best intel will retain the most coveted ad inventory.
At the same time, SSPs and DSPs, capable of securely processing bid requests with first-party data, will command a bigger share of the advertising market. SSP/DSP-owned data clean rooms can be a solid offering for prominent brands. At the same time, integrating with existing players can make your ad business more attractive to customers.
Contact Xenoss to receive personalized consultation on adapting your AdTech product to the new market realities.


